ATI Radeon X800 Pro and XT Platinum Edition: R420 Arrives
by Derek Wilson on May 4, 2004 10:28 AM EST- Posted in
- GPUs
The R420 Vertex Pipeline
The point of the vertex pipeline in any GPU is to take geometry data, manipulate it if needed (with either fixed function processes, or a vertex shader program), and project all of the 3D data in a scene to 2 dimensions for display. It is also possible to eliminate unnecessary data from the rendering pipeline to cut out useless work (via view volume clipping and backface culling). After the vertex engine is done processing the geometry, all the 2D projected data is sent to the pixel engine for further processing (like texturing and fragment shading).
The vertex engine of R420 includes 6 total vertex pipelines (R3xx has four). This gives R420 a 50% per clock increase in peak vertex shader power per clock cycle.
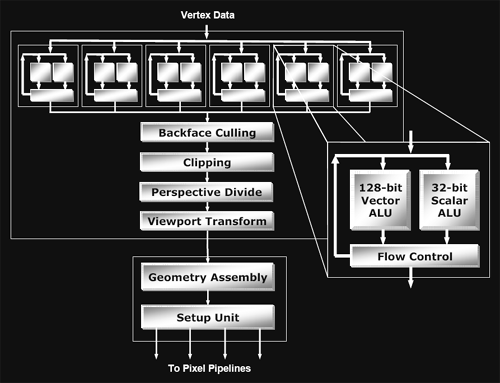
Looking inside an individual vertex pipeline, not much has changed from R3xx. The vertex pipeline is laid out exactly the same, including a 128bit vector math unit, and a 32bit scalar math unit. The major upgrade R420 has had from R3xx is that it is now able to compute a SINCOS instruction in one clock cycle. Before now, if a developer requested the sine or cosine of a number in a vertex shader program, R3xx would actually compute a taylor series approximation of the answer (which takes longer to complete). The adoption of a single cycle SINCOS instruction by ATI is a very smart move, as trigonometric computations are useful in implementing functionality and effects attractive to developers. As an example, developers could manipulate the vertices of a surface with SINCOS in order to add ripples and waves (such as those seen in bodies of water). Sine and cosine computations are also useful in more basic geometric manipulation. Overall, R420 has a welcome addition in single cycle SINCOS computation.
So how does ATI's new vertex pipeline layout compare to NV40? On a major hardware "black box" level, ATI lacks the vertex texture unit featured in NV40 that's required for shader model 3.0's vertex texturing support. Vertex texturing allows developers to easily implement any effect which would benefit from allowing texture data to manipulate geometry (such as displacement mapping). The other major difference between R420 and NV40 is feature set support. As has been widely talked about, NV40 supports Shader Model 3.0 and all the bells and whistles that come along with it. R420's feature set support can be described as an extended version of Shader Model 2.0, offering a few more features above and beyond the R3xx line (including more support of longer shader programs, and more registers).
What all this boils down to is that we are only seeing something that looks like a slight massaging of the hardware from R300 to R420. We would probably see many more changes if we were able too peer deeper under the hood. From a functionality standpoint, it is sometimes hard to see where performance comes from, but (as we will see even more from the pixel pipeline) as graphics hardware evolves into multiple tiny CPUs all laid out in parallel, performance will be effected by factors traditionally only spoken of in CPU analysis and reviews. The total number of internal pipeline stages (rather than our high level functionality driven pipeline), cache latencies, the size of the internal register file, number of instructions in flight, number of cycles an instructions takes to complete, and branch prediction will all come heavily into play in the future. In fact, this review marks the true beginning of where we will be seeing these factors (rather than general functionality and "computing power") determine the performance of a generation of graphics products. But, more on this later.
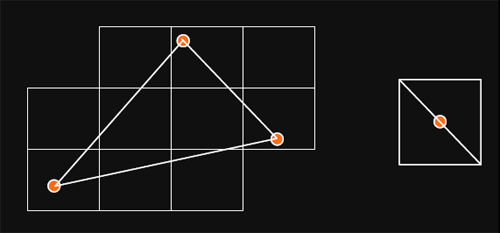
After leaving the vertex engine portion of R420, data moves into the setup engine. This section of the hardware takes the 2D projected data from the vertex engine, generates triangles and point sprites (particles), and partitions the output for use in the pixel engine. The triangle output is divided up into tiles, each of which are sent to a block of four pixel pipelines (called a quad pipeline by ATI). These tiles are simply square blocks of projected pixel data, and have nothing to do with "tile based rendering" (front to back rendering of small portions of the screen at a time) as was seen in PowerVR's Kyro series of GPUs.
Now we're ready to see what happens on the per-pixel level.








95 Comments
View All Comments
saechaka - Tuesday, May 4, 2004 - link
wow. very impressive. i was set on getting an nvidia but just don't know anymorePhiro - Tuesday, May 4, 2004 - link
The message is clear; Matrox has failed!Brickster - Tuesday, May 4, 2004 - link
Show me the money!MemberSince97 - Tuesday, May 4, 2004 - link
Advanced features are worthless if your driver team keeps breaking them..f11 - Tuesday, May 4, 2004 - link
kinda starting to feel sorry for nvidia now. each generation they stuff their cards with more feautures than they need to, end end up with a slower and more featured card. If anyone's expecting SM3 to be a big hit, remember that the original FX line had lots of extensions to DX9 and they never really made much a difference.