<b>Updated</b> CPU Cheatsheet - Seven Years of Covert CPU Operations
by Jarred Walton on August 28, 2004 9:00 AM EST- Posted in
- CPUs
Duron and Athlon
I won't bother going into details of the early Athlon and Duron processors. They were great in their day, but they're getting to be rather long in the tooth. If there is a strong demand for more details on these processors, I will add them at a later point, but for now I simply recommend that you bite the bullet and upgrade.
For those interested in some historical information, here are a few more tidbits. The early Argon, Pluto and Orion Athlon chips had L2 cache chips contained within the Slot A cartridge. This cache could run at 1/2, 2/5, or 1/3 of the core clock speed - the faster the core, the lower the ratio. This led to situations where, for example, a 700 MHz Athlon with 350 MHz L2 would outperform the more expensive 750/300, or the 850/340 would beat the 900/300 due to the slower cache. Generally speaking, performance comparisons between the Athlon and Pentium III chips of the day were neck-and-neck affairs, with each side winning some benchmarks. Athlon had better x87 floating point performance, while Intel generally won out with features like MMX and SSE - at least in applications that were properly optimized.
The socket A processors switched to an integrated full-speed L2 cache, but the cache was half as large. The increased speed and reduced latencies, however, more than made up for the decrease in cache size. At this time, AMD was able to actually surpass Intel in raw performance for a period of time. The Athlon Thunderbird eventually reached 1.4 GHz, while the Pentium III tried for 1.13 GHz and failed. Later versions of the Pentium III dubbed Tualatin would eventually reach 1.4 GHz, but those only came after the introduction of the Pentium 4. Athlon during these times was the chip for gaming systems.
One other item worth noting is that all of the Athlon and Duron systems used the EV6 bus protocol acquired from DEC/Alpha. This was a double-pumped system bus, which improved performance relative to older buses like that used in P6 motherboards. The bus speeds listed in the charts are the base bus speed, which is then multiplied by the CPU multiplier to arrive at the final CPU speed. However, due to the double-pumping, many motherboards will list the bus speed as the doubled value. The actual performance increased gained from the doubling of the bandwidth is not as large as some might expect, but it probably accounts for somewhere between 5 to 15 percent of the total performance of the architecture, depending on the application.
The Athlon 64 and Opteron processors, meanwhile, have switched to a HyperTransport bus running at 800 MHz on the early chips and 1 GHz on socket 939 chips. The main benefit of the HT bus is that it doesn't require as many traces (wires), so it makes motherboard layouts somewhat easier to design. This also allows for multiple high-speed bus connections when used in SMP systems without resorting to designs with more layers.
Athlon XP and Sempron Processors
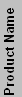 |
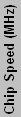 |
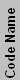 |
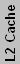 |
 |
 |
| Athlon XP (Desktop) & Sempron (Desktop Value) | |||||
| Athlon XP 1500+ | 1333 | Palomino | 256 | 133.3 | 10.0X |
| Athlon XP 1600+ | 1400 | Palomino | 256 | 133.3 | 10.5X |
| Athlon XP 1700+ | 1467 | Palomino/TBA | 256 | 133.3 | 11.0X |
| Athlon XP 1800+ | 1533 | Palomino/TBA | 256 | 133.3 | 11.5X |
| Sempron 2200+ | 1500 | Thoroughbred B | 256 | 166.7 | 9.0X |
| Athlon XP 1900+ | 1600 | Palomino/TBA | 256 | 133.3 | 12.0X |
| Athlon XP 2000+ | 1667 | Palomino/TBA | 256 | 133.3 | 12.5X |
| Athlon XP 2000+ | 1667 | Thorton | 256 | 133.3 | 12.5X |
| Athlon XP 2000+ | 1533 | Barton | 512 | 133.3 | 11.5X |
| Athlon XP 2100+ | 1733 | Palomino/TBA | 256 | 133.3 | 13.0X |
| Sempron 2400+ | 1667 | Thoroughbred B | 256 | 166.7 | 10.0X |
| Athlon XP 2200+ | 1800 | TBA/TBB | 256 | 133.3 | 13.5X |
| Athlon XP 2200+ | 1800 | Thorton | 256 | 133.3 | 13.5X |
| Sempron 2500+ | 1750 | Thoroughbred B | 256 | 166.7 | 10.5X |
| Athlon XP 2200+ | 1667 | Barton | 512 | 133.3 | 12.5X |
| Sempron 2600+ | 1833 | Thoroughbred B | 256 | 166.7 | 11.0X |
| Athlon XP 2400+ | 2000 | Thoroughbred B | 256 | 133.3 | 15.0X |
| Athlon XP 2400+ | 2000 | Thorton | 256 | 133.3 | 15.0X |
| Athlon XP 2400+ | 1800 | Barton | 512 | 133.3 | 13.5X |
| Athlon XP 2500+ | 1867 | Barton | 512 | 133.3 | 14.0X |
| Sempron 2800+ | 2000 | Thoroughbred B | 256 | 166.7 | 12.0X |
| Athlon XP 2600+ | 2133 | Thoroughbred B | 256 | 133.3 | 16.0X |
| Athlon XP 2500+ | 1833 | Barton | 512 | 166.7 | 11.0X |
| Athlon XP 2600+ | 2083 | Thoroughbred B | 256 | 166.7 | 12.5X |
| Athlon XP 2600+ | 2000 | Barton | 512 | 133.3 | 15.0X |
| Athlon XP 2600+ | 1917 | Barton | 512 | 166.7 | 11.5X |
| Athlon XP 2700+ | 2167 | Thoroughbred B | 256 | 166.7 | 13.0X |
| Athlon XP 2800+ | 2250 | Thoroughbred B | 256 | 166.7 | 13.5X |
| Athlon XP 2800+ | 2083 | Barton | 512 | 166.7 | 12.5X |
| Athlon XP 3000+ | 2167 | Barton | 512 | 166.7 | 13.0X |
| Athlon XP 3000+ | 2100 | Barton | 512 | 200 | 10.5X |
| Athlon XP 3200+ | 2200 | Barton | 512 | 200 | 11.0X |
| *** All system buses for Athlon XP, Sempron, Athlon 64, and Opteron are "double pumped", so their data rate is twice the bus speed. The multiplier is based off the listed speed. | |||||
Many of the processors listed in the charts were not commonly available, so they may not be well known. Some of these parts were shipped to OEMs who had special requirements, for example they might want to use cheaper PC2100 RAM with a Barton core. Some of the listed chips might also have been mobile parts which were mistakenly listed in the wrong table. However, the majority of these chips actually do exist in various PCs. Note also that some parts were likely to be seen more in overseas markets than in the US. If you are sure that a part is incorrect or doesn't exist, feel free to post a comment or send an email.
Athlon XP tweaked some of the finer details of the Athlon architecture to improve performance. Since XP was also going up against Pentium 4 instead of Pentium III, AMD (re)introduced model numbers and began their "clock speed isn't everything" campaign. According to AMD, the XP line was rated in terms of performance relative to the Thunderbird core, but few people actually believe that. It was almost surely market driven, as the Pentium 4 was scaling rapidly in clock speed, and the Athlon cores couldn't possibly keep up in raw MHz. And of course, AMD is correct that clock speed isn't everything - average instructions executed per clock (IPC) multiplied by clock speed would give you the real instruction throughput. Unfortunately, coming up with a precise measurement of IPC is virtually impossible - it varies depending on the code executed. Still, clock-for-clock, Athlons are definitely faster than P4 chips, and the PR ratings were relatively accurate, at least in the beginning.
As the "processor wars" continued, both companies released tweaked designs. Thoroughbred was a process shrink that brought higher clock speeds, but not as high as initially desired. A reworked Thoroughbred B core - which added an extra layer to the core, among other things - helped raise the clock limit a bit more and allowed Athlon XP to eventually reach 2250 MHz. Note that Thoroughbred B cores can often overclock to 2.3 to 2.4 GHz with sufficient cooling, while the A versions are often limited to ~2.1 GHz.
After Thoroughbred, AMD added more cache with the Barton core, and readjusted their model numbers accordingly, since more cache brought more performance. This was really where the model numbers started to become suspect, though, since Intel had also added more cache and increased bus speeds without "adjusting" any model numbers. The 2500+, 2600+ and 2800+ tended to struggle a bit in keeping up with their Intel counterparts, but the real problem came when Intel released the 200 MHz (800 FSB) "C" version of their Pentium 4. The jump to 3200+ with the 200 MHz FSB really only kept the Athlon XP competitive with the P4 2.8C in overall performance comparisons. Of course, here the model names were a stroke of genius, as many people simply assumed that a 3200+ really was the equivalent of the 3.2C.
Athlon XP-Mobile Processors
|
|
|
|
|
|
| Athlon XP-M (Mobile) | |||||
| Athlon XP-M 850 | 850 | Palomino | 256 | 100 | 8.5X |
| Athlon XP-M 900 | 900 | Palomino | 256 | 100 | 9.0X |
| Athlon XP-M 950 | 950 | Palomino | 256 | 100 | 9.5X |
| Athlon XP-M 1000 | 1000 | Palomino | 256 | 100 | 10.0X |
| Athlon XP-M 1100 | 1100 | Palomino | 256 | 100 | 11.0X |
| Athlon XP-M 1200 | 1200 | Palomino | 256 | 100 | 12.0X |
| Athlon XP-M 1400+ | 1200 | Thoroughbred | 256 | 133.3 | 9.0X |
| Athlon XP-M 1500+ | 1300 | Palomino | 256 | 100 | 13.0X |
| Athlon XP-M 1600+ | 1400 | Palomino | 256 | 100 | 14.0X |
| Athlon XP-M 1500+ | 1333 | Thoroughbred | 256 | 133.3 | 10.0X |
| Athlon XP-M 1600+ | 1400 | Thoroughbred | 256 | 133.3 | 10.5X |
| Athlon XP-M 1700+ | 1467 | Thoroughbred | 256 | 133.3 | 11.0X |
| Athlon XP-M 1800+ | 1533 | Thoroughbred | 256 | 133.3 | 11.5X |
| Athlon XP-M 1900+ | 1600 | Thoroughbred | 256 | 133.3 | 12.0X |
| Athlon XP-M 1900+ | 1467 | Barton | 512 | 133.3 | 11.0X |
| Athlon XP-M 2000+ | 1667 | Thoroughbred | 256 | 133.3 | 12.5X |
| Athlon XP-M 2000+ | 1533 | Barton | 512 | 133.3 | 11.5X |
| Athlon XP-M 2100+ | 1600 | Barton | 512 | 133.3 | 12.0X |
| Athlon XP-M 2200+ | 1800 | Thoroughbred | 256 | 133.3 | 13.5X |
| Athlon XP-M 2200+ | 1667 | Barton | 512 | 133.3 | 12.5X |
| Athlon XP-M 2400+ | 1800 | Barton | 512 | 133.3 | 13.5X |
| Athlon XP-M 2500+ | 1867 | Barton | 512 | 133.3 | 14.0X |
| Athlon XP-M 2600+ | 2000 | Barton | 512 | 133.3 | 15.0X |
| Athlon XP-M 2800+ | 2133 | Barton | 512 | 133.3 | 16.0X |
| *** All system buses for Athlon XP, Sempron, Athlon 64, and Opteron are "double pumped", so their data rate is twice the bus speed. The multiplier is based off the listed speed. | |||||
There's not really a whole lot to say about the Mobile AMD processors. They are identical to their desktop counterparts, except they run on lower voltages and can run at reduced clock speeds to save power. Later on, the Athlon XP-M processors gained tremendous popularity due to their unlocked multipliers, which allowed them to overclock very well, as you could keep the bus speed close to the standard 200 MHz.
There are some OEM parts as well in the Mobile Athlon market which use a different socket than the standard 462 pin socket A. For the Athlon XP, there is a 563 pin version, and for Athlon 64 there is a 638 pin version. Further details and information on these parts is, at present, lacking.
Athlon 64 and Opteron Processors
|
|
|
|
|
|
 |
| Athlon 64 & "Performance" Sempron | ||||||
| Sempron 3100+ | 1800 | Paris* | 256 | 200 | 9.0X | 754 |
| Athlon 64 2800+ | 1800 | Clawhammer | 512 | 200 | 9.0X | 754 |
| Athlon 64 2800+ | 1800 | Newcastle | 512 | 200 | 9.0X | 754 |
| Athlon 64 3000+ | 2000 | Clawhammer | 512 | 200 | 10.0X | 754 |
| Athlon 64 3000+ | 2000 | Newcastle | 512 | 200 | 10.0X | 754 |
| Athlon 64 3200+ | 2000 | Clawhammer | 1024 | 200 | 10.0X | 754 |
| Athlon 64 3200+ | 2200 | Newcastle | 512 | 200 | 11.0X | 754 |
| Athlon 64 3400+ | 2200 | Clawhammer | 1024 | 200 | 11.0X | 754 |
| Athlon 64 3400+ | 2400 | Newcastle | 512 | 200 | 12.0X | 754 |
| Athlon 64 3500+ | 2200 | Newcastle | 512 | 200 | 11.0X | 939 |
| Athlon 64 3700+ | 2400 | Clawhammer | 1024 | 200 | 12.0X | 754 |
| Athlon 64 FX-51 | 2200 | Sledgehammer | 1024 | 200 | 11.0X | 940 |
| Athlon 64 3700+ | 2600 | Newcastle | 512 | 200 | 13.0X | 754 |
| Athlon 64 3800+ | 2400 | Newcastle | 512 | 200 | 12.0X | 939 |
| Athlon 64 FX-53 | 2400 | Sledgehammer | 1024 | 200 | 12.0X | 940 |
| Athlon 64 FX-53 | 2400 | Sledgehammer | 1024 | 200 | 12.0X | 939 |
|
|
|
|
|
|
| Opteron** | |||||
| Opteron x40 | 1400 | Sledgehammer | 1024 | 200 | 7.0X |
| Opteron x42 | 1600 | Sledgehammer | 1024 | 200 | 8.0X |
| Opteron x44 | 1800 | Sledgehammer | 1024 | 200 | 9.0X |
| Opteron x46 | 2000 | Sledgehammer | 1024 | 200 | 10.0X |
| Opteron x48 | 2200 | Sledgehammer | 1024 | 200 | 11.0X |
| Opteron x50 | 2400 | Sledgehammer | 1024 | 200 | 12.0X |
| * The Paris core does not support 64-bit computing. It is included with the Athlon 64 because of the socket and because the integrated memory controller puts it ahead of the Athlon XP in performance. | |||||
| ** All Opterons are available in 1xx, 2xx, and 8xx versions. x=1 is for single processor systems, x=2 is for up to dual processor systems, and x=8 is for up to octal processor systems. | |||||
| *** All system buses for Athlon XP, Sempron, Athlon 64, and Opteron are "double pumped", so their data rate is twice the bus speed. The multiplier is based off the listed speed. | |||||
With the Athlon 64, as the name suggests AMD added support for 64-bit addresses and integers. This was done by widening their pathways and registers, but it wasn't a radical redesign of the core Athlon architecture. It has a pipeline that was increased to 12/17 stages, it got SSE2 support added, and the system bus was switched to a HyperTransport bus. The longer pipelines allow it to scale to somewhat higher clockspeeds, and the HyperTransport buses - there are three in the Opteron - allow for better SMP, but the core remains essentially the same. The addition of x86-64 support has garnered a lot of attention, but so far it's pretty much marketing hype. It has potential to improve performance once 64-bit support arrives, but that potential has not yet been realized in the mainstream market. The scientific and academic community, however, has greeted the introduction of affordable 64-bit processing with open arms. Most consumers, meanwhile, are stuck waiting for Windows XP-64.
The reason for the superior performance of the Athlon 64 - in current 32-bit code as well as in 64-bit code to a lesser extent - lies mostly with the integrated memory controller, which dramatically reduces memory latencies. In effect, it helps to turn system RAM into a very large but still relatively slow L3 cache. It also continues to reduce memory latencies as clock speeds increase. Memory latencies on the Athlon XP were roughly 81 ns at 3200+ speeds, and the P4 3.2C was around 77 ns latency. Meanwhile, the Athlon 64 3400+ comes in at an astonishingly low 48 ns. As mentioned before, those latency figures are getting somewhat close to L3 cache values - for example, the L3 cache in a 3.06 GHz Xeon is about 10 ns. It's still four times slower, but it's also twice as fast as RAM on a P4 system.
No better example of this can be found than the newly introduced Paris core, a.k.a. Sempron 3100+. At 1.8 GHz, it is substantially slower than the fastest Athlon XP in core speed, and yet in typical use it outperforms even the Athlon XP 3200+. This from a part that has half as much cache as the Barton and Newcastle cores! The only area where it fails to keep up is in tasks that generally fit within the L1/L2 cache of the CPU, i.e. certain encoding tasks. In that case, the lack of raw clockspeed is a hindrance.
Of course, reduced latency isn't the entire story of the Athlon 64. In 64-bit mode, the number of useable registers for both integer and floating point operations has been doubled. Depending on the code being run, this could potentially bring 10 to 20 percent more performance. Certain applications that make heavy use of 64-bit integers can also benefit from the added 64-bit support, for example cryptography and encoding tools. However, MMX and SSE have provided alternative means of improving 64-bit integer performance for many years now - they just require more programming effort to realize.








74 Comments
View All Comments
JarredWalton - Wednesday, September 1, 2004 - link
Jenand - thanks for the information. There are certainly some errors in the Itanium charts, but very few people seem to know much about the architecture, so I haven't gotten any corrections. Most of the future IA64 chips are highly speculative in terms of featurs.Incidentally, it looks like Tukwilla (and Dimona) will be 4 core designs, with motherboards support 4 CPUs, thus "16C" - or something like that. As for Fanwood, I really don't know much about it other than the name and some speculation that it *might* be the same as Madison9M. Or it might be a Dual Processor version of Madison, which is multi-processor.
http://endian.net/details.asp?ItemNo=3835
http://www.xbitlabs.com/news/cpu/display/200311101...
At the very least, Fanwood will have more than just a 9 MB cache configuration, it's probably safe to say.
JarredWalton - Wednesday, September 1, 2004 - link
If Prescott and Pentium M both use the exact same branch predictor, then yes, the Prescott would be more accurate than Banias. However, with the doubling of the cache size on Dothan, I can't imagine Intel would leave it with inferior branch prediction. So perhaps it goes something like this in terms of branch prediction accuracy:P6 cores
Willamette/Northwood
Banias
Prescott
Dothan
Possibly with the last two on the same level.
I'm still waiting to see if we can get pipeline stage information from Intel, but I have encountered several other sources online that refer to the Willamette/Northwood as having a 28 stage pipeline. Guess there's no use in beating a dead horse, though - either Intel will pass on information and we can have a definite, or it will remain an unknown. Don't hold your breath on Intel, though. :)
IntelUser2000 - Wednesday, September 1, 2004 - link
"Intel claims that the combination of the loop detector and indirect branch predictor gives Centrino a 20% increase in overall branch prediction accuracy, resulting in a 7% real performance increase."Sure, but Prescott also has Pentium M's branch predictor enhancements in addition to the enhancements made to Willamette, while Pentium M didn't get Willamette's enhancements, just the indirect branch predictor.
Yes it says 20% increase, but from what? PIII, P4? Prescott?
jenand - Tuesday, August 31, 2004 - link
There are a few errors and some missing information on the IPF sheet:1) Fanwood will get 4M(?) L3 or so, not 9M. You probably mixed it up with its bigger brother Madison9M, both to be released soon.
2)Foxton and Pelleston are code names for technologies used in Montecito, not CPU code names.
3) Dimona and Tukwila are "pairs" (just like Madison/Deerfield, Madison9M/Fanwood and Montecito/Millington) both will be made on 45nm nodes and are scheduled for 2007. Montvale is probably a shrink of Montecito or Millington to the 65nm node and will probably be launched in 2006.
4) Montecito and Millington will be made on 90nm and use the PAC-611 socket. The FSB of Montecito will be 100MHZ for compatibility reasons, but will also be introduced at a higher FSB (166MHz?) late in 2005.
5) Fanwood will probably get 100MHz and 133MHz FSB, not 166MHz. Same goes for Millington.
I hope it was helpful. Please note that I don't have any internal information I only read the rumors.
JarredWalton - Tuesday, August 31, 2004 - link
Heh... one last link. Hannibal discusses why the PM is able to have better branch prediction with a smaller BTB in his article about the PM. At the bottom of the following page is where he specifically discusses the improvements to the P4:http://castor.arstechnica.com/cpu/004/pentium-m/pe...
And his summary: "Intel claims that the combination of the loop detector and indirect branch predictor gives Centrino a 20% increase in overall branch prediction accuracy, resulting in a 7% real performance increase. Of course, the usual caveats apply to these statistics, i.e. the increase in branch prediction accuracy and that increase's effect on real-world performance depends heavily on the type of code being run. Improved branch prediction gives the PM a leg up not only in terms of performance but in terms of power efficiency as well. Because of its improved branch prediction capabilities, the PM wastes less energy speculatively executing code that it will then have to throw away once it learns that it mispredicted a branch."
He could be wrong, of course, but personally I trust his research on CPUs more than a lot of other sites - after all, he does *all* architectures, not just x86. Hopefully, Intel will provide me (Kristopher) with some direct answers. :)
JarredWalton - Tuesday, August 31, 2004 - link
In case that last wasn't clear, I'm not saying the CPU detection is really that blatant, but if the CPU detection is required for accuracy, it *could* be that bad. Rumor, by the way, puts the Banias core at 14 or 15 stages, and the Dothan *might* add one more stage.JarredWalton - Tuesday, August 31, 2004 - link
Regarding Pentium M, I believe the difference to the branch prediction isn't merely a matter of size. It has a new indirect branch predictor, as well as some other features. Basically, P-M is designed for power usage first, and so they made a lot more elegant design decisions at times, whereas Northwood and Prescott are more of a brute force approach.As for the differences between various AT articles, it's probably worth pointing out that this is the first article I've ever written for Anandtech, so don't be too surprised that it has some differences of opinion. Who's right? It's difficult to say.
As for the program mentioned in that thread, I downloaded it and ran it on my Athlon 64. You know what the result was? 13.75 to 13.97 cycles. Since a branch miss doesn't actually necessitate a flush of the entire pipeline, that would mean that it's estimating the length of the A64 as probably 15 or 16 stages - off by a factor of 33% or so. If it were off by that same amount on Prescott, that would put Prescott at [drumroll...] 23 stages.
I've passed on some questions for Intel to Kristopher Kubuki, so maybe we can get the real poop. Until then, it's still a case of "nobody knows for sure". Estimating pipeline lengths based off of a program that reports accurate results on P4 and Northwood cores is at best a guess, I would say.
Incidentally, I looked at the source code, and while I haven't really studied it extensively, there is a CPU detection, so the mispredict penalty is calculated differently on P4, P6, and *other* architectures. Maybe it's okay, maybe it's not, but if accurate results are dependent on CPU detection, that sort of calls the whole thing into question.
if CPU=P6 then printf("12 stages.\n")
else if CPU=P4 then printf("10 stages.\n")
else if....
Hopefully, it *is* relatively accurate, but as I said, ~14 cycles mispredict penalty on an Athlon 64 is either incorrect, or AMD actually created a 15 stage pipeline and didn't tell anyone. :)
IntelUser2000 - Monday, August 30, 2004 - link
Okay, I don't know further than that. But one question: Since the old P4 article from Anandtech states 10 stage pipelin P6 core, and Prescott is claimed to have 31 stages and you claim otherwise, it tells that there is individual errors in the SAME site. So whether Hannibal's site can be trusted is doubtful because of that fact too, no? Also, take a look at this link: http://www.realworldtech.com/forums/index.cfm?acti...I asked a guy in the forums about it and that link is about the responses to it.
One example Hannibal's site may be wrong is this: http://arstechnica.com/cpu/004/prescott-future/pre...
At the end of that link it says: "There's actually another reason why the Pentium M won't benefit as much from hyperthreading. The Pentium M's branch predictor is superior to Prescott's, so the Pentium M is less likely to suffer from instruction-related pipeline stalls than the Prescott. This improved branch prediction, in combination with its shorter pipeline, means improved execution efficiency and less of a need for something like hyperthreading."
Now, we know Pentium M has shorter pipeline than Prescott but better branch prediction? I really think its wrong, since one of the major improvements of BOTH Prescott and Pentium M in branch prediction is improvements in indirect branch prediction, PLUS, Prescott and Northwood I believe, has bigger BTB buffer size, somewhere in the order of 8x, because Pentium M used indirect branch prediction improvements to save die size and putting more buffer definitely doesn't coincide with that.
Fishie - Monday, August 30, 2004 - link
This is a great summary of the processor cores. I would like to see the same thing done with video cards.JarredWalton - Monday, August 30, 2004 - link
#49 - Did you even read the links in post #44? Did you read post #44? Let's make it clear: the Willamette and Northwood cores were 20 stage pipelines coupled to an 8 stage prefetch/decode unit (which feeds into the trace cache). This much, we know for sure. The Prescott core appears to be 23 stages with the same (essentially) 8 stage prefetch/decode unit. So, you can call early P4 cores 20 stages, in which case Prescott is 23 stages, or you can call Prescott 31 stages, in which case early P4 cores were 28 stages.If you look at the chart in the link to Anandtech, notice how the P4 pipeline is lacking in fetch and decode stages? Anyway, there's nothing that says the AT chart you linked from Aug 2000 is the DEFINITIVE chart. People do make errors, and Intel hasn't been super forthcoming about their pipelines. I'll give you a direct link to where Hannibal talks about the P6 and P4 pipelines - take it up with him if you must:
http://arstechnica.com/cpu/004/pentium-1/pentium-1...
Synopsis: In the AT picture, the P6 pipeline has 2 fetch and 2 decode stages, while Hannibal describes it as 3.5 BTB/Fetch stages and 2.5 Decode stages.
http://arstechnica.com/cpu/01q2/p4andg4e/p4andg4e-...
Here, the P4 and G4e architectures are compared, but if you read this page, it explains the trace cache and how it effects things. Specifically: "Only when there's an L1 cache miss does that top part of the front end kick in in order to fetch and decode instructions from the L2 cache. The decoding and translating steps that are necessitated by a trace cache miss add another eight pipeline stages onto the beginning of the P4's pipeline, so you can see that the trace cache saves quite a few cycles over the course of a program's execution."
-----------------------
Further reading:
http://episteme.arstechnica.com/eve/ubb.x?a=tpc&am...
The comments in the "Discuss" section of the article contain further elaboration by Hannibal on the Prescott: "The 31 stages came from the fact that if you include the trace cache in the pipeline (which Intel normally doesn't and I didn't here) then the P4's pipeline isn't 20 stages but 28 (at least I think that's the number). So if you add three extra stages to 28 you get 31 total stages."
The problem is, Intel simply isn't coming out and directly stating what the facts are. It *could* be that Prescott is really 31 stages (as Intel has said) plus another 8 to 10 stages of fetch/decode logic, putting the "total" length at 39 to 41 stages. However, given the clockspeed scaling - rather, the lack thereof - it would not be surprising to have it "only" be 23 stages plus 8 fetch/decode stages. After all, the die shrink to 90 nm should have been able to push the Northwood core to at least 4 GHz, which seems to be what the Prescott is hitting as well.
Unless you actually work for Intel and can provide a definitive answer? I, personally, would love some charts from Intel documenting all of the stages of both the initial NetBurst pipeline as well as the Prescott pipeline. (Maybe I should mention this to Anand...?)