GeForce 6200 TurboCache: PCI Express Made Useful
by Derek Wilson on December 15, 2004 9:00 AM EST- Posted in
- GPUs
Architecting for Latency Hiding
RAM is cheap. But it's not free. Making and selling extremely inexpensive video cards means as few components as possible. It also means as simple a board as possible. Fewer memory channels, fewer connections, and less chance for failure. High volume parts need to work, and they need to be very cheap to produce. The fact that TurboCache parts can get by with either 1 or 2 32-bit RAM chips is key in its cost effectiveness. This probably puts it on a board with a few fewer layers than higher end parts, which can have 256-bit connections to RAM.But the only motivation isn't saving costs. NVIDIA could just stick 16MB on a board and call it a day. The problem that NVIDIA sees with this is the limitations that would be placed on the types of applications end users would be able to run. Modern games require framebuffers of about 128MB in order to run at 1024x768 and hold all the extra data that modern games require. This includes things like texture maps, normal maps, shadow maps, stencil buffers, render targets, and everything else that can be read from or draw into by a GPU. There are some games that just won't run unless they can allocate enough space in the framebuffer. And not running is not an acceptable solution. This brings us to the logical combination of cost savings and compatibility: expand the framebuffer by extending it over the PCI Express bus. But as we've already mentioned, main memory appears much "further" away than local memory, so it takes much longer to either get something from or write something to system RAM.
Let's take a look at the NV4x architecture without TurboCache first, and then talk about what needs to change.
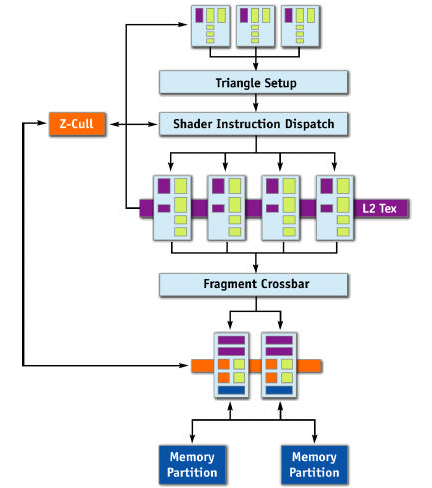
The most obvious thing that will need to be added in order to extend the framebuffer to system memory is a connection from the ROPs to system memory. This will allow the TurboCache based chip to draw straight from the ROPs into things like back or stencil buffers in system RAM. We would also want to connect the pixel pipelines to system RAM directly. Not only do we need to read textures in normally, but we may also want to write out textures for dynamic effects.
Here's what NVIDIA has offered for us today:
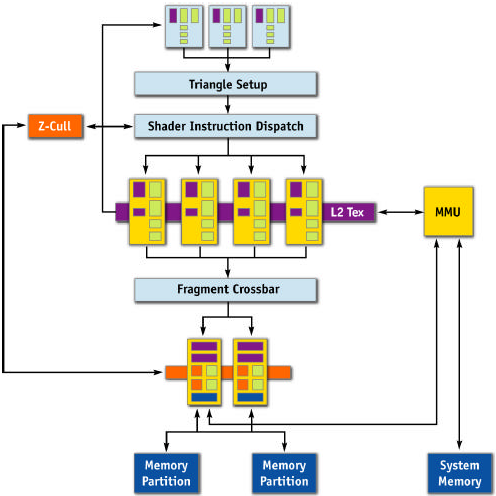
The parts in yellow have been rearchitected to accommodate the added latency of working with system memory. The only part that we haven't talked about yet is the Memory Management Unit. This block handles the requests from the pixel pipelines and ROPs and acts as the interface to system memory from the GPU. In NVIDIA's words, it "allows the GPU to seamlessly allocate and de-allocate surfaces in system memory, as well as read and write to that memory efficiently." This unity works in tandem with part of the Forceware driver called the TurboCache Manager, which allocates and balances system and local graphics memory. The MMU provides the system level functionality and hardware interface from GPU to system and back while the TurboCache Manager handles all the "intelligence" and "efficiency" behind the operations.
As far as memory management goes, the only thing that is always required to be on local memory is the front buffer. Other data often ends up being stored locally, but only the physical display itself is required to have known, reliable latency. The rest of local memory is treated as a something like the framebuffer and a cache to system RAM at the same time. It's not clear as to the architecture of this cache - whether it's write-back, write-through, has a copy of the most recently used 16MBx or 32MBs, or is something else altogether. The fact that system RAM can be dynamically allocated and deallocated down to nothing indicates that the functionality of local graphics memory as a cache is very adaptive.
NVIDIA hasn't gone into the details of how their pixel pipes and ROPs have been rearchitected, but we have a few guesses.
It's all about pipelining and bandwidth. A GPU needs to draw hundreds of thousands of independent pixels every frame. This is completely different from a CPU, which is mostly built around dependant operations where one instruction waits on data from another. NVIDIA has touted the NV4x as a "superscalar" GPU, though they haven't quite gone into the details of how many pipeline stages it has in total. The trick to hiding latency is to make proper use of bandwidth by keeping a high number of pixels "in flight" and not waiting for the data to come back to start work on the next pixel.
If our pipeline is long enough, our local caches are large enough, and our memory manager is smart enough, we get cycle of processing pixels and reading/writing data over the bus such that we are always using bandwidth and never waiting. The only down time should be the time that it takes to fill the pipeline for the first frame, which wouldn't be too bad in the grand scheme of things.
The big uncertainty is the chipset. There are no guarantees on when the system will get data back from system memory to the GPU. Worst case latency can be horrible. It's also not going to be easy to design around worst case latencies, as NVIDIA is a competitor to other chipset makers who aren't going to want to share that kind of information. The bigger the guess at the latency that they need to cover, the more pixels NVIDIA needs to keep in flight. Basically, covering more latency is equivalent to increasing die size. There is some point of diminishing returns for NVIDIA. But the larger presence that they have on the chipset side, the better off they'll be with their TurboCache parts as well. Even on the 915 chipset from Intel, bandwith is limited across the PCI Express bus. Rather than a full 4GB/s up and 4GB/s down, Intel offers only 3GB/s up and 1GB/s down, leaving the TurboCache architecture with this:
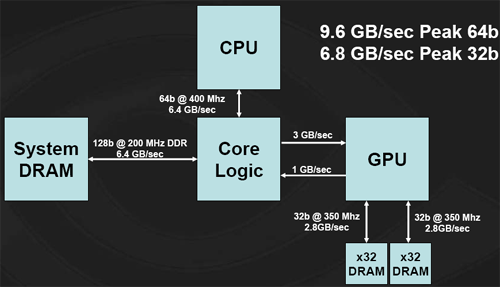
Graphics performance is going to be dependant on memory bandwidth. The majority of the bandwidth that the graphics card has available comes across the PCI Express bus, and with a limited setup such as this, the 6200 TuboCache will see a performance hit. NVIDIA has reported seeing something along the lines of a 20% performance improvement by moving from a 3-down, 1-up architecture to a 4-down, 4-up system. We have yet to verify these numbers, but it is not unreasonable to imagine this kind of impact.
The final thing to mention is system performance. NVIDIA only maps free idle pages from RAM using "an approved method for Windows XP." It doesn't lock anything down, and everything is allocated and freed on they fly. In order to support 128MB of framebuffer, 512MB of system RAM must be installed. With more system RAM, the card can map more framebuffer. NVIDIA chose 512MB as a minimum because PCI Express OEM systems are shipping with no less. Under normal 2D operation, as there is no need to store any more data than can fit in local memory, no extra system resources will be used. Thus, there should be no adverse system level performance impact from TurboCache.








43 Comments
View All Comments
PrinceGaz - Thursday, December 16, 2004 - link
#28- see page 2 of the article, the text just above the diagram near the bottom of the page "Even on the 915 chipset from Intel, bandwith is limited across the PCI Express bus. Rather than a full 4GB/s up and 4GB/s down, Intel offers only 3GB/s up and 1GB/s down..."#25- I'd also always assumed that all PCIe x16 sockets could support 4GB/s both ways, this is the first time I've heard otherwise. And it isn't even 4/1, it's 3/1 according to the info given.
Derek- is this limited PCIe x16 bandwidth common to all chipsets?
DerekWilson - Thursday, December 16, 2004 - link
We tested the 32MB 64-bit $99 version of the card that "supports" a 128MB framebuffer.#31 is correct -- the maximum of 112 of 96 (or 192 for the 256 MB version) of system RAM is not staticly mapped. It's always avalable to the system under 2D operation. Under 3D, it's not likely that the entire framebuffer would be absolutely full at any given time anyway.
Alphafox78 - Thursday, December 16, 2004 - link
doesnt it dynamicly allocate the extra memory it needs? so this would just affect games then if it needed more, not regular apps that done need lots of video memory.rqle - Thursday, December 16, 2004 - link
so total cost of these card is the card price + (price of 128MB worth of DDR at the time)?Maverick2002 - Thursday, December 16, 2004 - link
I'm likewise confused. At the end of the review they say:"There will also be a 64MB 64-bit TC part (supporting 256MB) available for $129 coming down the pipeline at some point, though we don't have that part in our labs just yet."
Didn't they just test this card???
KalTorak - Thursday, December 16, 2004 - link
#25 - huh? (I have no idea what that term means in the context of PCIe, and I know PCIe pretty well...)KayKay - Thursday, December 16, 2004 - link
I think this is a good product, i think it could be a very good part for companies like dell, if they include it into their systems. cheaper than the x300se's they currently include, but better performance, and will appeal to that type of customermczak - Wednesday, December 15, 2004 - link
#24, from the description it sounds like for the radeon igp there is no problem with both using sideport and system memory simultaneously for directly rendering into (the interleaved mode exactly sounds like part of all buffers would be allocated in system memory, though maybe that's not what is meant).IntelUser2000 - Wednesday, December 15, 2004 - link
WTF!! I never new Intel's 915 chipsets used 4/1GB implementation of PCI Express!! Even Anandtech's own article didn't say that they said 4/4.DerekWilson - Wednesday, December 15, 2004 - link
As far as I understand Hypermemory, it is not capable of rendering directly to system memory.Also, when Hypermemory needs to go to allocate system RAM for anything, there is a very noticeable performance hit.
We tested the 16MB/32-bit and the 32MB/64-bit
The 64MB version available is only 64-bit ... NVIDIA uses four 8M x 16 memory chips.