Workstation Graphics: AGP Cross Section 2004
by Derek Wilson on December 23, 2004 4:14 PM EST- Posted in
- GPUs
3Dlabs Wildcat Realizm 200 Technology
Fixed function processing may still be the staple of the workstation graphics world, but 3Dlabs isn't going to be left behind in terms of technology. The new Wildcat Realizm GPU supports everything that one would expect from a current generation graphics processor, including VS 2.0, and PS 3.0 level programmability. The hardware itself weighs in at about 150M transistors and is fabbed on a 130nm process. We're taking a look at the top end AGP SKU from 3Dlabs, but the highest end offering essentially places two of these GPUs on one board, connected by a vertex/scalability unit, but we'll take a look at that when we explore PCI Express workstations. The pipeline of the Wildcat Realizm 200 looks very much like what we expect a 3D pipeline to look.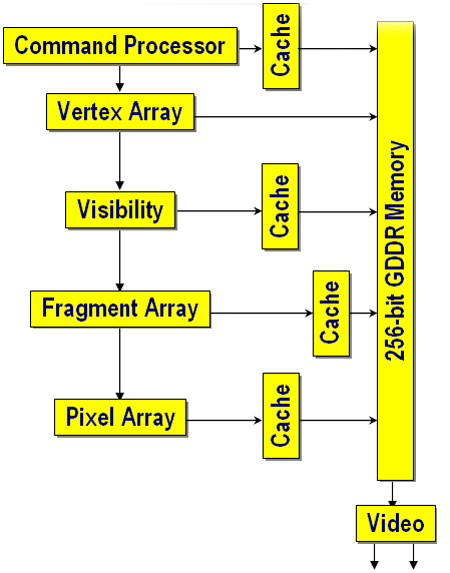
When we start to peel away the layers, we see a very straightforward and powerful architecture. We'll start by explaining everything, except for the Vertex Array and the Fragment Array (which will get a little more detailed investigation shortly).
The Command Processor is responsible for keeping track of command streams coming into the GPU. Of interest is the fact that it supports the NISTAT and NICMD registers for isochronous AGP operation. This allows the card to support requests by applications for a constant stream of data at guaranteed intervals. On cards without isochronous AGP support, cards must be capable of handling arbitrarily long delays in request fulfillment based on the capabilities of the chipset. This feature is particularly interesting for real-time broadcast video situations in which dropped frames are not an option. Of course, it only works with application support, and we don't have a good test as to the impact of isochronous AGP operation either.
Visibility is computed via a Hierarchical Z algorithm. Essentially, large tiles of data are examined at a time. If the entire tile is occluded, it can all be thrown out. 3Dlabs states that their visibility algorithm is able to discard up to 1024 multi-samples per clock. This would fit the math for a 16x16 pixel tile with 4x multi-samples per pixel. This is actually 256 pixels, which is the same size block as ATI's Hierarchical Z engine. And keep in mind, these are maximal numbers; if the tile is partially occluded, only part of the data can be thrown out.
What 3Dlabs calls the Pixel Array, it is circuitry that takes care of AA, compositing, color conversion, filtering, and everything else that might need to happen to the final image before scan out. This is similar in function, for example, to the ROP in an NVIDIA part. The Wildcat Realizm GPU is capable of outputting multiple formats from the traditional to fp16 data. This means that it can handle things like 10-bit alpha blending, or 10-bit LUT for monitors that support it. On the basic hardware level, 3Dlabs defines this block as a 16x 16-bit floating point SIMD array. This means that 4 fp16 RGBA pixels can be processed by the Pixel Array simultaneously. In fact, all the programmable processing parts of the Wildcat Realizm are referred to terms of SIMD arrays. This left us with a little math to compute based on the following information and this layout shot:
Vertex Array: 16-way, high-accuracy 36-bit float SIMD array, DX9 VS 2.0 capable
Fragment Array: 48-way, 32-bit float component SIMD array, DX9 PS 3.0 capable

For the Vertex Array, we have a 16x 36-bit floating point SIMD array. Since there are two physical Vertex Shader Arrays in the layout of the chip as shown above, and we are talking about SIMD (single instruction multiple data) arrays, it stands to reason that each array can handle 8x 36-bit components at maximum. It's not likely that this is one large 8-wide SIMD block. If 3Dlabs followed ATI and NVIDIA, they could organize this as one 6-wide unit and one 2-wide unit, executing two vec3 operations on one SIMD block and two scalar operations on the other. This would give them two "vertex pipelines" per array. Without knowing the granularity of the SIMD units, or how the driver manages allocating resources among the units, it's hard to say exactly how much work can get done per clock cycle. Also, as there are two physically separate vertex arrays, each half of the vertex processing block is likely to share resources like registers and caches. It is important to note that the vertex engine here is 36-bits wide. The extra 4 bits, which are above and beyond what anyone else offers, actually delivers 32-bits of accuracy in the final vertex calculation. Performing operations at the same accuracy level as the data stored essentially builds in a level of noise to the result. This is because intermediate results of calculations are truncated to the accuracy of the stored data. This is a desirable feature to maintain high precision vertex accuracy, but we haven't been able to come up with a real world application that pushes other parts to a place where 32-bit vertex hardware breaks down and the 36-bit hardware is able to show a tangible advantage.
The big step for vertex hardware accuracy will need to be 64-bit. For CAD/CAM applications, a db of 64-bit values is kept. These double values are very important for manufacturing, but currently, graphics hardware isn't robust enough to display anything but single precision floating point data. Already high transistor counts would get unmanageable with current fab technology.
Other notable features of the vertex pipeline of the Wildcat Realizm products include support for 32 hardware fixed function hardware lights, and VS 2.0 level functionality with a maximum of 1000 instructions. Not supporting VS 3.0 while implementing full PS 3.0 support is an interesting choice for 3Dlabs. Right now, fixed function support is more important to the CAD/CAM market and arguably more important to the workstation market overall. But, geometry instancing could really help geometry limited applications when working with scenes full of multiple objects. Vertex textures might also be useful in the DCC market. Application support does push hardware vendors to include and exclude certain features, but we really would have liked to see full SM 3.0 support in the Wildcat Realizm product line.
The Fragment Array consists of three physical blocks that make up a 48-way 32-bit floating point SIMD array. This means that we 16x 32-bit components being processed in each of the three physical blocks at any given time. What we can deduce from this is that each of the three physical blocks share common register and cache resources and very likely operate on four pixels with strong locality of reference at a time. It's possible that 3Dlabs could organize the distribution of pixels over their pipeline in a similar manner to either ATI or NVIDIA, but we don't have enough information to determine what's going on at a higher level. We also can't say how granular 3DLab's SIMD arrays are, which means that we don't know just how much work they can get done per clock cycle. In the worst case, the Wildcat Realizm is equipped with 4x 4-wide SIMD units per physical fragment block. This would mean that operating on one component at a time would make 3 components idle while waiting for the fourth. It's much more likely that they implemented a combination of smaller units and are able to divide the work among them, as both ATI and NVIDIA have done. We know that 3Dlabs units are all vector units, which means that we are limited to combinations of 2-, 3-, and 4-wide vector blocks.
Unfortunately, without more information, we can't draw conclusions on DX9 co-issue or dual-issue per pipeline capabilities of the part. No matter what resources are under the hood, it's up to the compiler and driver to handle the allocation of everything that the GPU offers to the GLSL or HLSL code running on it. On a side note, it is a positive sign to see a third company confirm the major design decisions that we have seen both ATI and NVIDIA make in their hardware. With the 3Dlabs Wildcat Realizm 200 coming to market as a 4 vertex/12 pixel pipe architecture, it will certainly be exciting to see how things stack up in the final analysis.
The Fragment Array supports PS 3.0 and 256000 instruction length shader programs. The Fragment Array also supports 32 textures in one clock. This, again, seems to be a total limitation per clock. The compiler would likely distribute resources as needed. If we look at this in the same way that we look at the ATI or NVIDIA hardware, we'd see that we can access 2.6 textures per pixel. This could also translate to 2/3 of the components loading their own texture if needed, and if the driver supported it. 3Dlabs also talks about the Wildcat Realizm's ability to handle "cascaded dependant textures" in shaders. Gracefully handling a large number of dependent textures is useful, but it will bring shader hardware to a crawl. It's unclear how many depth/stencil operations that the Realizm is capable of in one pass, but there is a separate functional block for such processing shown on the image above.
One very important thing to note is that the Wildcat Realizm calculates all pixel data in fp32, but stores pixel data in an fp16 (5s10) format. This has the effect of increasing memory bandwidth from what it would be with fp32, while decreasing accuracy. The precentage by which percision is decreased depends on the data being processed and algorithms used. The fp32->fp16 and fp16->fp32 conversions are all done with zero performance impact between the GPU and memory. It's very difficult to test the accuracy of the fragment engine. We've heard that it comes out somewhere near 30-bit accuracy from 3Dlabs, and it very well could. We would still like to see an empirical test that could determine the absolute accuracy for a handful of common shaders before we sign off on anything. This is at least an interesting solution to the problem of balancing a 32-bit and 16-bit solution. Moving all that pixel data can really impact bandwidth in shader intensive applications, and we saw just how hard the impact can be with NVIDIA's original 32-bit NV30 architecture. We've heard that it is possible to turn off the 16-bit storage feature and have the Realizm GPU store full 32-bit precision data, but we have yet to see this option in the driver or as a tweak. Obviously, we would like to get our hands on a switch like this to evaluate both the impact on performance and image quality.
Another important feature to mention about the Wildcat Realizm is its virtual memory support. The Realizm supports 16GB of virtual memory. This allows big memory applications to swap pages out of local graphics memory to system RAM if needed. On the desktop side, this isn't something that we've seen a real demand or need for, but workstation parts definitely benefit from it. Speed is absolutely useful, but more important than speed is actually being able to visualize a necessary data set. There are data sets and workloads that just can't fit in local framebuffers. The Wildcat Realizm 200 has 512 MB of local memory, but if needed, it could have swapped paged out up to the size of our free idle system memory. The 3Dlabs virtualization system doesn't support paging to disk and isn't managed by windows, but the 3Dlabs driver. Despite the limitations of the implementation, the solution is elegant, necessary, and extraordinarily useful to those who need massive amounts of RAM available to their visualization system.
On the display side, the Wildcat Realizm 200 is designed to push the limits of 9MP panels, video walls, and multi-system displays. With dual 10-bit 400MHz RAMDACs, two dual-link DVI-I connections, and support for an optional Multiview kit with genlock and framelock capabilities, the Wildcat Realizm is built to drive vast numbers of pixels. The scope of this article is limited to single display 3D applications, but if there is demand, we may explore the capabilities of professional cards to drive extremely high resolutions and 2 or more monitors.
Even though it can be tough to sort through at times, this low level description of hardware is nicer than what we get from ATI and NVIDIA in some ways because we get a chance to see what the hardware is actually doing. The block diagram high level look that others provide us can be very useful in understanding what a pipeline does, but it obfuscates the differences in respective implementations. We would love to have a combination of the low level physical description of hardware that 3Dlabs has given us and high level descriptions that we get from ATI and NVIDIA. Of course, then we could go build our own GPUs and skip the middle man.








25 Comments
View All Comments
Sword - Friday, December 24, 2004 - link
Hi again,I want to add to my first post that there were 2 parts and a complex assembly (>110 very complex parts without simplified rep).
The amount of data to process was pretty high (XP shows >400 Mb and it can goes up to 600 Mb).
About the specific features, I believe that most of the CAD users do not use them. People like me, mechanical engineers and other engineers, are using the software like Pro/E, UGS, Solidworks, Inventor and Catia for solid modeling without any textures or special effects.
My comment was really to point that the high end features seams useless in real world application for engineering.
I still believe that for 3D multimedia content, there is place for high-end workstation and the specviewperf benchmark is a good tool for that.
Dubb - Friday, December 24, 2004 - link
how about throwing in soft-quadro'd cards? when people realize with a little effort they can take a $350 6800GT to near-q4000 performance, that changes the pricing issue a bit.Slaimus - Friday, December 24, 2004 - link
If the Realizm 200 performs this well, it will be scary to see the 800 in action.DerekWilson - Friday, December 24, 2004 - link
dvinnen, workstation cards are higher margin -- selling consumer parts may be higher volume, but the competition is harder as well. Creative would have to really change their business model if they wanted to sell consumer parts.Sword, like we mentioned, the size of the data set tested has a large impact on performance in our tests. Also, Draven31 is correct -- a lot depends on the specific features that you end up using during your normal work day.
Draven31, 3dlabs drivers have improved greatly with the Realizm from what we've seen in the past. In fact, the Realizm does a much better job of video overlay playback as well.
Since one feature of the Quadro and Realizm cards is their ability to run genlock/framelock video walls, perhaps a video playback/editing test would make a good addition to our benchmark suite
Draven31 - Friday, December 24, 2004 - link
Coming up with the difference between the spec viewperf tests and real-world 3d work means finding out which "high-end card' features that the test is using and then turning them off in the tests. With NVidia cards, this usually starts with antialiased lines. It also depends on whether the application you are running even uses these features... in Lightwave3D, the 'pro' cards and the consumer cards are very comparable performance-wise because it doesn't use these so-called 'high-end' features very extensively.And while they may be faster in some Viewperf tests, 3dLabs drivers generally suck. Having owned and/or used several, I can tell you any app that uses DirectX overlays as part of its display routines is going to either be slow or not work at all. For actual application use, 3dLabs cards are useless. I've seen 3dLabs cards choke on directX apps, and that includes both games and applications that do windowed video playback on the desktop (for instance, video editing and compositing apps)
Sword - Thursday, December 23, 2004 - link
Hi everyone,I am a mechanical engineer in Canada and I am a fan of anandtech.
I made last year a very big comparison of mainstream vs workstation video card for our internal use (the company I work for).
The goal was to compare the different systems (and mainly video cards) to see if in Pro-Engineer and the kind of work with do we could take real advantage of high-end workstation video card.
My conclusion is very clear : in specviewperf there is a huge difference between mainstream video card and workstation video card. BUT, in the day-to-day work, there is no real difference in our reaults.
To summarize, I made a benchmark in Pro/E using the trail files with 3 of our most complex parts. I made comparison in shading, wireframe, hidden line and I also verified the regeneration time for each part. The benchmark was almost 1 hour long. I compared 3D Labs product, ATI professionnal, Nvidia professionnal and Nvidia mainstream.
My point is : do not believe specviewperf !! Make your own comparison with your actual day-to-day work to see if you really have to spend 1000 $ per video cards. Also, take the time to choose the right components so you minimize the calculation time.
If anyone at Anandtech is willing to take a look at my study, I am willing to share the results.
Thank you
dvinnen - Thursday, December 23, 2004 - link
I always wondered why Creative (they own 3dLabs) never made a consumer edition of the Wildcat. Seems like a smallish market when it wouldn't be all that hard to expand into consumer cards.Cygni - Thursday, December 23, 2004 - link
Im surprised by the power of the Wildcat, really... great for the dollar.DerekWilson - Thursday, December 23, 2004 - link
mattsaccount,glad we could help out with that :-)
there have been some reports of people getting consumer level driver to install on workstatoin class parts, which should give better performance numbers for the ATI and NVIDIA parts under games if possible. But keep in mind that the trend in workstation parts is to clock them at lower speeds than the current highest end consumer level products for heat and stability reasons.
if you're a gamer who's insane about performance, you'd be much better off paying $800 on ebay for the ultra rare uberclocked parts from ATI and NVIDIA than going out and getting a workstation class card.
Now, if you're a programmer, having access to the workstation level features is fun and interesting. But probably not worth the money in most cases.
Only people who want workstation class features should buy workstation class cards.
Derek Wilson
mattsaccount - Thursday, December 23, 2004 - link
Yes, very interesting. This gives me and lots of others something to point to when someone asks why they shouldn't get the multi-thousand dollar video card if they want top gaming performance :)