Itanium - is there light at the end of the tunnel?
by Johan De Gelas on November 9, 2005 12:05 AM EST- Posted in
- CPUs
EPIC 101
The basics of EPIC (Explicitly Parallel Instruction-set Computing) is a mix of typical RISC and VLIW (very long instruction word) features. From RISC, it copies a relatively straightforward instruction set, a very large register file (128 registers for integer and floating point) and three operand instructions that use registers. Using three operands, two source registers and a destination register (R1 = R2 +R3), instead of two (R2 = R1 + R2), does the calculation job in less instructions and avoids - given enough registers - unnecessary trips to hidden registers or the L1- cache.
Load and Store instruction are used to getting data and instructions from the memory; instructions that actually calculate do not reference memory locations as in x86.
A fixed instruction length makes it much easier to decode, like RISC ISA's, and completely contrary to the x86 instruction set where decoding is a very painful job that requires many pipeline stages. These additional stages are necessary to obtain high clockspeeds, but they make the pipeline unnecessarily long and the branch prediction penalty worse. The Itanium 2 has only an 8-stage pipeline, but is still able to clock up to 1.7 GHz (conservative) using a 130 nm process. Compared to the Xeon MP (130 nm), which clocked up to 3 GHz, it needed a 28-stage pipeline (20 after Trace cache + 8 before) to achieve less than a twice as high a clock speed.
Inside the hardware, the Itanium uses instruction bundles that are 128 bits large. Such a bundle consists of three 41 bit instructions and one 5 bit template. It is this 5 bit template that contains the "compiler grouping" information about the parallelism between the different instructions. Thus, compilers will use this template to tell the CPU what instructions should be issued together. It gets even better; this template also contains an end-of-bundle bit. With this bit, the compiler can indicate whether or not the bundle is finished after the first three instructions or if the CPU should chain two (or even more) bundles together.
Another 6 bits specify the 64 combinations of predication that allow the compiler to eliminate branches, as each instruction can be conditional. So, instead of:
The instruction grouping and elimination of most of the branches opens the way to higher ILP. So, while the Athlon 64 can sustain at most 3 instructions per clock cycle, the Itanium can fetch, decode, issue, execute and retire 2 bundles or 6 instructions per clock cycle.
Contrary to old VLIW designs, the compiler is not obliged to put the instruction in a strict order in a bundle. But there are certain limitations to what kind of instruction mix you can find inside a bundle, as you can see in the table below.
Cache hints, data and instruction pre-fetching and data speculation are a few of the tricks that the Itanium and its compiler can use to keep the caches full with the right instructions and data. Those tricks and the large caches are essential to the Itanium: a L2 cache miss can result in a real stall, as the CPU cannot check dynamically for independent instruction to issue.
In a nutshell, the Itanium has the following advantages:
The basics of EPIC (Explicitly Parallel Instruction-set Computing) is a mix of typical RISC and VLIW (very long instruction word) features. From RISC, it copies a relatively straightforward instruction set, a very large register file (128 registers for integer and floating point) and three operand instructions that use registers. Using three operands, two source registers and a destination register (R1 = R2 +R3), instead of two (R2 = R1 + R2), does the calculation job in less instructions and avoids - given enough registers - unnecessary trips to hidden registers or the L1- cache.
Load and Store instruction are used to getting data and instructions from the memory; instructions that actually calculate do not reference memory locations as in x86.
A fixed instruction length makes it much easier to decode, like RISC ISA's, and completely contrary to the x86 instruction set where decoding is a very painful job that requires many pipeline stages. These additional stages are necessary to obtain high clockspeeds, but they make the pipeline unnecessarily long and the branch prediction penalty worse. The Itanium 2 has only an 8-stage pipeline, but is still able to clock up to 1.7 GHz (conservative) using a 130 nm process. Compared to the Xeon MP (130 nm), which clocked up to 3 GHz, it needed a 28-stage pipeline (20 after Trace cache + 8 before) to achieve less than a twice as high a clock speed.
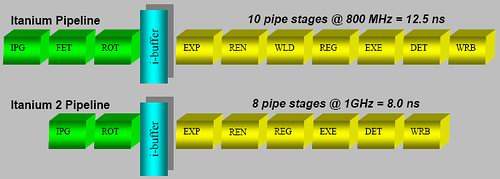
The short Itanium and Itanium 2 pipeline
Inside the hardware, the Itanium uses instruction bundles that are 128 bits large. Such a bundle consists of three 41 bit instructions and one 5 bit template. It is this 5 bit template that contains the "compiler grouping" information about the parallelism between the different instructions. Thus, compilers will use this template to tell the CPU what instructions should be issued together. It gets even better; this template also contains an end-of-bundle bit. With this bit, the compiler can indicate whether or not the bundle is finished after the first three instructions or if the CPU should chain two (or even more) bundles together.

IA-64 instruction bundle
Another 6 bits specify the 64 combinations of predication that allow the compiler to eliminate branches, as each instruction can be conditional. So, instead of:
Compare R1 to 0 (IF...)You get:
If false jump to Label
R2 =R3 ("Then" instructions)
Label: (Else instructions)
R2 =R1
On the condition that R=0, R2=R3So you eliminate the conditional jump ("If false, jump to") and replace the whole "IF THEN ELSE" clause with an instruction that checks the register and then moves the contents from R3 to R2 in one sweep. Conditional jumps are dependant on the instruction before it and they have to wait until the "Compare R1 to 0" instruction is done. Conditional instructions, however, travel through the pipeline for execution and don't have to wait for anything. You could say that the "IF" part and "Then" part are fused together. For the "else" part, you get:
On the condition that R<>0, R2 = R1Predication makes the code more compact, and eliminates branches and dependencies. Branches can make up 20% of your code, easily. So, with one branch every 5 instructions, it is very hard to issue many instructions in parallel. By converting them into conditional instructions, you eliminate the dependencies and the ILP can get much higher.
The instruction grouping and elimination of most of the branches opens the way to higher ILP. So, while the Athlon 64 can sustain at most 3 instructions per clock cycle, the Itanium can fetch, decode, issue, execute and retire 2 bundles or 6 instructions per clock cycle.
Contrary to old VLIW designs, the compiler is not obliged to put the instruction in a strict order in a bundle. But there are certain limitations to what kind of instruction mix you can find inside a bundle, as you can see in the table below.
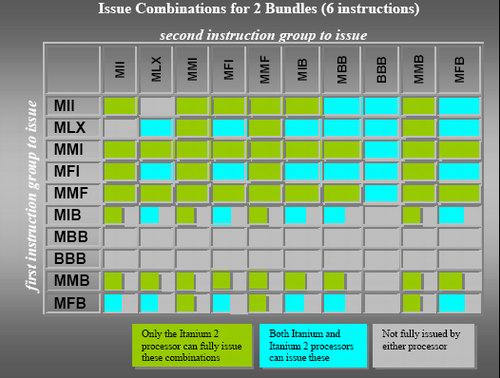
Possible bundles
Cache hints, data and instruction pre-fetching and data speculation are a few of the tricks that the Itanium and its compiler can use to keep the caches full with the right instructions and data. Those tricks and the large caches are essential to the Itanium: a L2 cache miss can result in a real stall, as the CPU cannot check dynamically for independent instruction to issue.
In a nutshell, the Itanium has the following advantages:
- Easy decoding leads to a shorter pipeline as less decoding work has to be done, so less stages are necessary;
- In order issue and execution means that dispatch hardware is much simpler, which leads to a shorter pipeline and less transistors;
- Removing conditional jumps and letting the compiler do the scheduling extracts more ILP; and
- 128 registers and the load/store model reduce the number of memory/cache accesses significantly,
- No out-of-order execution makes cache misses and pipelines stalls much more costly; and
- 128 registers and the whole bundle and group system make the instructions on average much longer than x86.








43 Comments
View All Comments
lifeguard1999 - Wednesday, November 9, 2005 - link
Johan has written a good article on the Itanium and its advantages. However, just because something is good from an engineers point of view, does not mean that it will be a market success. There is the business side of the equation that is just as important, and I will be looking forward to future articles on this.I live and play in the HPC world. Historically, this world has been small and based on (for lack of a better word), big-iron chips such as those found in the Cray C-90 (early 1990's technology) to the Cray X1E (today's tech). In the 1990's people clustered together "commodity" PCs (commonly called Beowulf Clusters) which culminated in 1997 Gordon Bell Prize at SC97 for a cluster of 16 Intel Pentium Pros (200 MHz). Today, these cluster-based supercomputers are everywhere (Cray sells a XT3 based on Opterons). The advantage of the cluster-based supercomputer is price/performance, or said another way: cost.
And that is where this ties back into the business case. Can Itanium compete based on cost? Now cost is more than just how much to produce the physical chip. There are systems adminstrator costs, cooling costs, user-needs-to-learn-to-program-it costs, etc. Cooling concerns are coming to the forefront now as supercomputers may need a dedicated power plant in the near future. Imagine, if you will, how much heat 10,000 Opterons can produce and much electricity it consumes (we only have 4096).
SGI was a big seller of supercomputers based on the MIPS chips (low power, low performance, but easy to use). They transitioned over to the Itanium chips and have had a successful run of supercomputers called the Altix. The problem is that anyone can buy a Opteron cluster supercomputer for much less cost than an Itanium supercomputer. While this is not the only reason for the decline of SGI and its recent delisting from the NYSE (inept management is the main reason) it is a contributing factor.
That leaves HP as the largest seller of Itaniums. Did I mention inept management two sentences back? Maybe I should mention it here again.
Itanium may be a great architecture, and it may survive and thrive. Right now however, it appears that there are dark days ahead.
highlandsun - Wednesday, November 9, 2005 - link
There are still a variety of problems that the Altix design can handle more easily than any cluster-based approach. I'm not convinced that the Altix architecture is tied to Itanium, though. It'd be cool to see an Altix-like machine based on Opterons.ksherman - Wednesday, November 9, 2005 - link
seems like a really good article! Too bad most of it goes over my head :(ceefka - Wednesday, November 9, 2005 - link
Me too, I can finally make some sense of what Itanium is all about. It may have potential in a technical sense but until it comes at an affordable price it doesn't stand a chance imho. It's not always the best tech that sells best, Intel knows ;-)xbdestroya - Wednesday, November 9, 2005 - link
Nice Article. I personally don't see too much of a future for Itanium with the environment it's presently operating in coupled with Intel's missteps, but I feel that for all the heat Itanium: 'The Project' often takes, the architecture itself is unduly maligned.Plus, I love to see articles analysing architectures other than the bread-and-butter x86 ones we're used to seeing. Some more on EPIC, Power... Sun/Fujitsu chips - maybe some NEC - let's spice things up!
There was one problem though with the article on the last page though:
"But the best x86 design - the AMD Opteron - does about 60% less work per clock cycle in integer, and about 115% less work per cycle in floating point than the Itanium."
How does something do 115% *less* work per cycle? Obviously not.
JohanAnandtech - Wednesday, November 9, 2005 - link
Mathematiques was never my best course. :-) Indeed the Itanium does 60% more integer work and 115% more FP.Calin - Thursday, November 10, 2005 - link
So the Opteron does just 62.5% integer work and 46.5% floating point work per clock cycle compared to Itanium.I learned this mostly after introduction of VAT in economy
snorre - Wednesday, November 9, 2005 - link
You write:"it is clear, however, that the Itanium has time on its side and is most likely the architecture with the highest potential."
No, that is not true by any standards. I've tested Itanium systems from day one, including several compilers and development tools and I don't see any high potential with this platform. It's over-expensive, under-performing and quite frankly a big flop.
Don't keep this pace maker going any further, please let it die in peace. Some good ideas just dosen't work well in practice, and EPIC is just another like them.
Starglider - Wednesday, November 9, 2005 - link
Here's a scenario I like to imagine. After many years of research, marketing and general toil Intel claim that their new Itanium-5 chip will finally be the one to popularise the platform. The day before the launch, AMD announce their new x86-64+++ architecture, which extends x86 (again) to allow a scheduling/cache/decoding-hints metadata stream interleaved with the main instruction stream. The new design combines the code density and dynamic optimisation of x86 with all the static optimisation power and execution width of Itanium (but done better becasue AMD have learned from Intel's mistakes), is binary compatible with legacy applications at full speed, and has AMD's onboard memory and PCI express controllers. AMD own 90% of the high-end space by the end of the year and Itanium is finally killed off. ;)dexvx - Wednesday, November 9, 2005 - link
You have no idea what you're talking about do you?I'd like to see a scheduler that is both dynamic and static at the same time.