ATI's New Leader in Graphics Performance: The Radeon X1900 Series
by Derek Wilson & Josh Venning on January 24, 2006 12:00 PM EST- Posted in
- GPUs
R580 Architecture
The architecture itself is not that different from the R520 series. There are a couple tweaks that found their way into the GPU, but these consist mainly of the same improvements made to the RV515 and RV530 over the R520 due to their longer lead time (the only reason all three parts arrived at nearly the same time was because of a bug that delayed the R520 by a few months). For a quick look at what's under the hood, here's the R520 and R580 vertex pipeline:
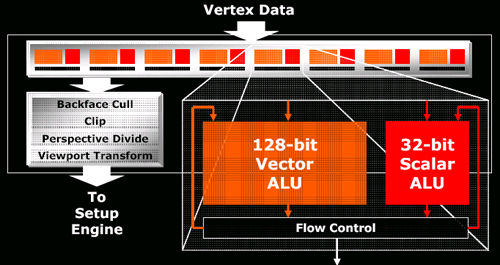
and the internals of each pixel quad:
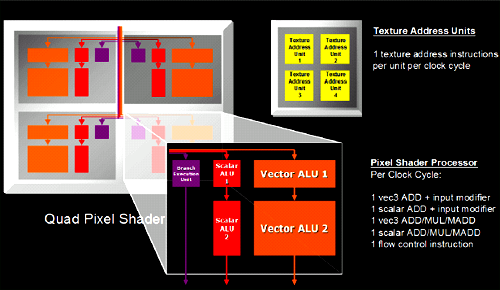
The real feature of interest is the ability to load and filter 4 texture addresses from a single channel texture map. Textures which describe color generally have four components at every location in the texture, and normally the hardware will load an address from a texture map, split the 4 channels and filter them independently. In cases where single channel textures are used (ATI likes to use the example of a shadow map), the R520 will look up the appropriate address and will filter the single channel (letting the hardware's ability to filter 3 other components go to waste). In what ATI calls it's Fetch4 feature, the R580 is capable of loading 3 other adjacent single channel values from the texture and filtering these at the same time. This effectively loads 4 and filters four times the texture data when working with single channel formats. Traditional color textures, or textures describing vector fields (which make use of more than one channel per position in the texture) will not see any performance improvement, but for some soft shadowing algorithms performance increases could be significant.
That's really the big news in feature changes for this part. The actual meat of the R580 comes in something Tim Allen could get behind with a nice series of manly grunts: More power. More power in the form of a 384 million transistor 90nm chip that can push 12 quads (48 pixels) worth of data around at a blisteringly fast 650MHz. Why build something different when you can just triple the hardware?
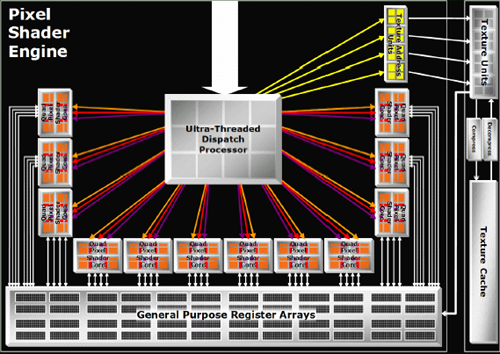
To be fair, it's not a straight tripling of everything and it works out to look more like 4 X1600 parts than 3 X1800 parts. The proportions work out to match what we see in the current midrange part: all you need for efficient processing of current games is a three to one ratio of pixel pipelines to render backends or texture units. When the X1000 series initially launched, we did look at the X1800 as a part that had as much crammed into it as possible while the X1600 was a little more balanced. Focusing on pixel horsepower makes more efficient use of texture and render units when processing complex and interesting shader programs. If we see more math going on in a shader program than texture loads, we don't need enough hardware to load a texture every single clock cycle for every pixel when we can cue them up and aggregate requests in order to keep available resources busy more consistently. With texture loads required to hide latency (even going to local video memory isn't instantaneous yet), handling the situation is already handled.
Other than keeping the number of texture and render units the same as the X1800 (giving the X1900 the same ratios of math to texture/fill rate power as the X1600), there isn't much else to say about the new design. Yes, they increased the number of registers in proportion to the increase in pixel power. Yes they increased the width of the dispatch unit to compensate for the added load. Unfortunately, ATI declined allowing us to post the HDL code for their shader pipeline citing some ridiculous notion that their intellectual property has value. But we can forgive them for that.
This handy comparison page will have to do for now.
The architecture itself is not that different from the R520 series. There are a couple tweaks that found their way into the GPU, but these consist mainly of the same improvements made to the RV515 and RV530 over the R520 due to their longer lead time (the only reason all three parts arrived at nearly the same time was because of a bug that delayed the R520 by a few months). For a quick look at what's under the hood, here's the R520 and R580 vertex pipeline:
and the internals of each pixel quad:
The real feature of interest is the ability to load and filter 4 texture addresses from a single channel texture map. Textures which describe color generally have four components at every location in the texture, and normally the hardware will load an address from a texture map, split the 4 channels and filter them independently. In cases where single channel textures are used (ATI likes to use the example of a shadow map), the R520 will look up the appropriate address and will filter the single channel (letting the hardware's ability to filter 3 other components go to waste). In what ATI calls it's Fetch4 feature, the R580 is capable of loading 3 other adjacent single channel values from the texture and filtering these at the same time. This effectively loads 4 and filters four times the texture data when working with single channel formats. Traditional color textures, or textures describing vector fields (which make use of more than one channel per position in the texture) will not see any performance improvement, but for some soft shadowing algorithms performance increases could be significant.
That's really the big news in feature changes for this part. The actual meat of the R580 comes in something Tim Allen could get behind with a nice series of manly grunts: More power. More power in the form of a 384 million transistor 90nm chip that can push 12 quads (48 pixels) worth of data around at a blisteringly fast 650MHz. Why build something different when you can just triple the hardware?
To be fair, it's not a straight tripling of everything and it works out to look more like 4 X1600 parts than 3 X1800 parts. The proportions work out to match what we see in the current midrange part: all you need for efficient processing of current games is a three to one ratio of pixel pipelines to render backends or texture units. When the X1000 series initially launched, we did look at the X1800 as a part that had as much crammed into it as possible while the X1600 was a little more balanced. Focusing on pixel horsepower makes more efficient use of texture and render units when processing complex and interesting shader programs. If we see more math going on in a shader program than texture loads, we don't need enough hardware to load a texture every single clock cycle for every pixel when we can cue them up and aggregate requests in order to keep available resources busy more consistently. With texture loads required to hide latency (even going to local video memory isn't instantaneous yet), handling the situation is already handled.
Other than keeping the number of texture and render units the same as the X1800 (giving the X1900 the same ratios of math to texture/fill rate power as the X1600), there isn't much else to say about the new design. Yes, they increased the number of registers in proportion to the increase in pixel power. Yes they increased the width of the dispatch unit to compensate for the added load. Unfortunately, ATI declined allowing us to post the HDL code for their shader pipeline citing some ridiculous notion that their intellectual property has value. But we can forgive them for that.
This handy comparison page will have to do for now.








120 Comments
View All Comments
Harkonnen - Tuesday, January 24, 2006 - link
Almost $900 CDN for the XTX and it only has a 1 year warranty?Main reason I would never buy an expensive ATi card is that right there.
smitty3268 - Tuesday, January 24, 2006 - link
The people who buy a card this expensive the first day it comes out won't keep it for a whole year, so the warranty doesn't matter. In 6 months another card will be out that makes this one look slow and they'll be spending even more money.DerekWilson - Tuesday, January 24, 2006 - link
Due to popular demand, we have added more percent increase performance comparison graphs to the performance breakdown that shows the performance relatoinships at lower resolutions.Let us know if there is anything else you'd like to see. Thanks!
Live - Tuesday, January 24, 2006 - link
The performance breakdown looks very good now! I would go so far as to say that this should be standard in future reviews.piroroadkill - Tuesday, January 24, 2006 - link
Using a lossy image format (JPEG) for image quality comparison screenshots seems kind of... pointless.But I guess you have to worry about bandwidth.
Josh Venning - Tuesday, January 24, 2006 - link
Thanks for the input all. Just to let you know we are dealing with some problems regarding our power numbers, but they should be up shortly. Thanks for being patient.Josh Venning - Tuesday, January 24, 2006 - link
One more thing.. We also caught a mistype on the graphs that we are in the process of correcting. The two crossfire systems we tested are the X1900 XTX Crossfire and the X1800 XT Crossfire. (we miss-labeled the latter "X1900 XT Crossfire") Sorry for any confusion this may have caused.smitty3268 - Tuesday, January 24, 2006 - link
Ah... That makes much more sense now. I was wondering why the XTX crossfire was doing so much better than the XT crossfire when the specs were so similar.SpaceRanger - Tuesday, January 24, 2006 - link
Problems with the publishing of them, or problems in the sense that it requires a direct link into a nuclear reactor to power properly??
DerekWilson - Tuesday, January 24, 2006 - link
our local nuclear plant ran us an extention cord just for this event :-)