ATI's New Leader in Graphics Performance: The Radeon X1900 Series
by Derek Wilson & Josh Venning on January 24, 2006 12:00 PM EST- Posted in
- GPUs
R580 Architecture
The architecture itself is not that different from the R520 series. There are a couple tweaks that found their way into the GPU, but these consist mainly of the same improvements made to the RV515 and RV530 over the R520 due to their longer lead time (the only reason all three parts arrived at nearly the same time was because of a bug that delayed the R520 by a few months). For a quick look at what's under the hood, here's the R520 and R580 vertex pipeline:
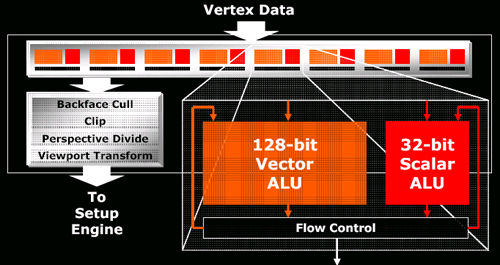
and the internals of each pixel quad:
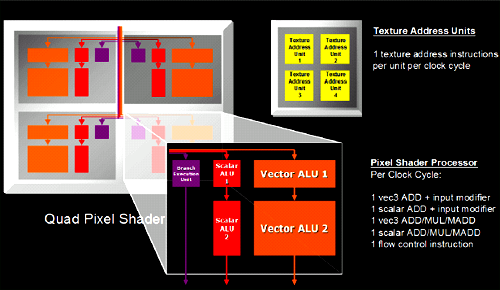
The real feature of interest is the ability to load and filter 4 texture addresses from a single channel texture map. Textures which describe color generally have four components at every location in the texture, and normally the hardware will load an address from a texture map, split the 4 channels and filter them independently. In cases where single channel textures are used (ATI likes to use the example of a shadow map), the R520 will look up the appropriate address and will filter the single channel (letting the hardware's ability to filter 3 other components go to waste). In what ATI calls it's Fetch4 feature, the R580 is capable of loading 3 other adjacent single channel values from the texture and filtering these at the same time. This effectively loads 4 and filters four times the texture data when working with single channel formats. Traditional color textures, or textures describing vector fields (which make use of more than one channel per position in the texture) will not see any performance improvement, but for some soft shadowing algorithms performance increases could be significant.
That's really the big news in feature changes for this part. The actual meat of the R580 comes in something Tim Allen could get behind with a nice series of manly grunts: More power. More power in the form of a 384 million transistor 90nm chip that can push 12 quads (48 pixels) worth of data around at a blisteringly fast 650MHz. Why build something different when you can just triple the hardware?
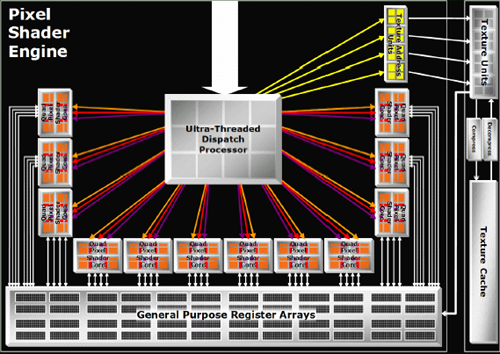
To be fair, it's not a straight tripling of everything and it works out to look more like 4 X1600 parts than 3 X1800 parts. The proportions work out to match what we see in the current midrange part: all you need for efficient processing of current games is a three to one ratio of pixel pipelines to render backends or texture units. When the X1000 series initially launched, we did look at the X1800 as a part that had as much crammed into it as possible while the X1600 was a little more balanced. Focusing on pixel horsepower makes more efficient use of texture and render units when processing complex and interesting shader programs. If we see more math going on in a shader program than texture loads, we don't need enough hardware to load a texture every single clock cycle for every pixel when we can cue them up and aggregate requests in order to keep available resources busy more consistently. With texture loads required to hide latency (even going to local video memory isn't instantaneous yet), handling the situation is already handled.
Other than keeping the number of texture and render units the same as the X1800 (giving the X1900 the same ratios of math to texture/fill rate power as the X1600), there isn't much else to say about the new design. Yes, they increased the number of registers in proportion to the increase in pixel power. Yes they increased the width of the dispatch unit to compensate for the added load. Unfortunately, ATI declined allowing us to post the HDL code for their shader pipeline citing some ridiculous notion that their intellectual property has value. But we can forgive them for that.
This handy comparison page will have to do for now.
The architecture itself is not that different from the R520 series. There are a couple tweaks that found their way into the GPU, but these consist mainly of the same improvements made to the RV515 and RV530 over the R520 due to their longer lead time (the only reason all three parts arrived at nearly the same time was because of a bug that delayed the R520 by a few months). For a quick look at what's under the hood, here's the R520 and R580 vertex pipeline:
and the internals of each pixel quad:
The real feature of interest is the ability to load and filter 4 texture addresses from a single channel texture map. Textures which describe color generally have four components at every location in the texture, and normally the hardware will load an address from a texture map, split the 4 channels and filter them independently. In cases where single channel textures are used (ATI likes to use the example of a shadow map), the R520 will look up the appropriate address and will filter the single channel (letting the hardware's ability to filter 3 other components go to waste). In what ATI calls it's Fetch4 feature, the R580 is capable of loading 3 other adjacent single channel values from the texture and filtering these at the same time. This effectively loads 4 and filters four times the texture data when working with single channel formats. Traditional color textures, or textures describing vector fields (which make use of more than one channel per position in the texture) will not see any performance improvement, but for some soft shadowing algorithms performance increases could be significant.
That's really the big news in feature changes for this part. The actual meat of the R580 comes in something Tim Allen could get behind with a nice series of manly grunts: More power. More power in the form of a 384 million transistor 90nm chip that can push 12 quads (48 pixels) worth of data around at a blisteringly fast 650MHz. Why build something different when you can just triple the hardware?
To be fair, it's not a straight tripling of everything and it works out to look more like 4 X1600 parts than 3 X1800 parts. The proportions work out to match what we see in the current midrange part: all you need for efficient processing of current games is a three to one ratio of pixel pipelines to render backends or texture units. When the X1000 series initially launched, we did look at the X1800 as a part that had as much crammed into it as possible while the X1600 was a little more balanced. Focusing on pixel horsepower makes more efficient use of texture and render units when processing complex and interesting shader programs. If we see more math going on in a shader program than texture loads, we don't need enough hardware to load a texture every single clock cycle for every pixel when we can cue them up and aggregate requests in order to keep available resources busy more consistently. With texture loads required to hide latency (even going to local video memory isn't instantaneous yet), handling the situation is already handled.
Other than keeping the number of texture and render units the same as the X1800 (giving the X1900 the same ratios of math to texture/fill rate power as the X1600), there isn't much else to say about the new design. Yes, they increased the number of registers in proportion to the increase in pixel power. Yes they increased the width of the dispatch unit to compensate for the added load. Unfortunately, ATI declined allowing us to post the HDL code for their shader pipeline citing some ridiculous notion that their intellectual property has value. But we can forgive them for that.
This handy comparison page will have to do for now.








120 Comments
View All Comments
DerekWilson - Tuesday, January 24, 2006 - link
this is where things get a little fuzzy ... when we used to refer to an architecture as being -- for instance -- 16x1 or 8x2, we refered to the pixel shaders ability to texture a pixel. Thus, when an application wanted to perform multitexturing, the hardware would perform about the same -- single pass graphics cut the performance of the 8x2 architecture in half because half the texturing poewr was ... this was much more important for early dx, fixed pipe, or opengl based games. DX9 through all that out the window, as it is now common to see many instructions and cycles spent on any given pixel.in a way, since there are only 16 texture units you might be able to say its something like 48x0.333 ... it really isn't possible to texture all 48 pixels every clock cycle ad infinitum. in an 8x2 architecture you really could texture each of 8 pixels with 2 textures every clock cycle forever.
to put it more plainly, we are now doing much more actual work with the textures we load, so the focus has shifted from "texturing" a pixel to "shading" a pixel ... or fragment ... or whatever you wanna call it.
it's entirely different then xenos as xenos uses a unified shader architecture.
interestingly though, R580 supports a render to vertex buffer feature that allows you to turn your pixel shaders into vertex processors and spit the output straight back into the incoming vertex data.
but i digress ....
aschwabe - Tuesday, January 24, 2006 - link
I'm wondering how a dual 7800GT/7800GTX stacked up against this card.i.e. Is the brand new system I bought literally 24 hours ago going to be able to compete?
Live - Tuesday, January 24, 2006 - link
SLI figures is all over the review. Go read and look at the graphs again.aschwabe - Tuesday, January 24, 2006 - link
Ah, my bad, thanks.DigitalFreak - Tuesday, January 24, 2006 - link
Go check out the review on hardocp.com. They have benchies for both the GTX 256 & GTX 512, SLI & non SLI.Live - Tuesday, January 24, 2006 - link
No my bad. I'm a bit slow. Only the GTX 512 SLI are in there. sorry!Viper4185 - Tuesday, January 24, 2006 - link
Just a few comments (some are being very picky I know)1) Why are you using the latest hardware with and old Seagate 7200.7 drive when the 7200.9 series is available? Also no FX-60?
2) Disappointing to see no power consumption/noise levels in your testing...
3) You are like the first site to show Crossfire XTX benchmarks? I am very confused... I thought there was only a XT Crossfire card so how do you get Crossfire XTX benchmarks?
Otherwise good job :)
DerekWilson - Tuesday, January 24, 2006 - link
crossfire xtx indicates that we ran a 1900 crossfire edition card in conjunction with a 1900 xtx .... this is as opposed to running the crossfire edition card in conjunction with a 1900 xt.crossfire does not synchronize GPU speed, so performance will be (slightly) better when pairing the faster card with the crossfire.
fx-60 is slower than fx-57 for single threaded apps
power consumption was supposed to be included, but we have had some power issues. We will be updating the article as soon as we can -- we didn't want to hold the entire piece in order to wait for power.
harddrive performance is not going to affect anything but load times in our benchmarks.
DigitalFreak - Tuesday, January 24, 2006 - link
See my comment above. They are probably running an XTX card with the Crossfire Edition master card.OrSin - Tuesday, January 24, 2006 - link
Are gamers going insane. $500+ for video card is not a good price. Maybe its jsut me but are bragging rights really worth thats kind of money. Even if you played a game thats needs it you should be pissed at the game company thats puts a blot mess thats needs a $500 card.