Out of Order execution: AMD versus Intel
To make this article more accessible and to make the differences between the AMD K8 and the new Intel Core architecture more clear, I tried to make both CPU diagrams in the same style. Here's the Core architecture overview: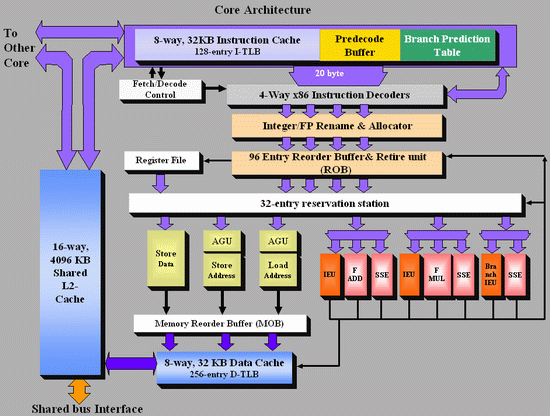
And here's the K8 architecture:
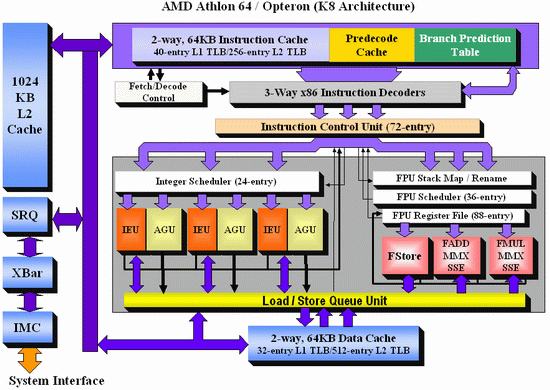
There are a few obvious differences: Core has bigger OoO buffers: the 96 entry ROB buffer is - also thanks to Macro-op fusion - quite a bit bigger than the 72 Entry Macro-op buffer of K8. The P6 architecture could order only 40 instructions, this was doubled to 80 in the P-M architecture (Banias, Dothan, Yonah), and now it's increased even further to 96 for the Core architecture. We've created a table which compares the most important architectural details of several current CPU families:
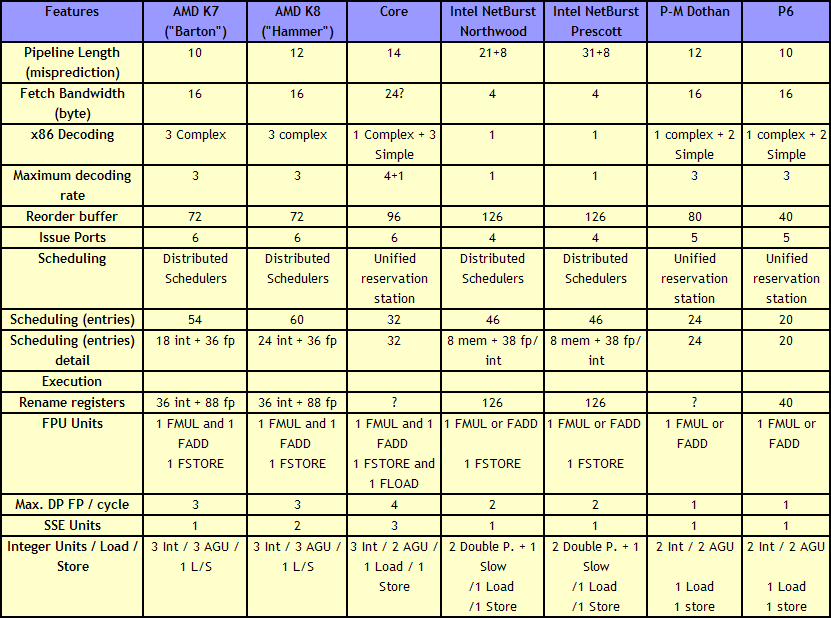 |
| Click to enlarge |
The Core architecture uses a central reservation station, while the Athlon uses distributed schedulers. The advantage of a central reservation station is that utilization is better, however distributed schedulers allow more entries. NetBurst also uses distributed schedulers.
Using a central reservation station is another clear example of how Core is in fact the "P8", the second big improvement of the P6 architecture. Just like the P6 architecture, it uses a Reservation Station (RS) and allocates a specific execution unit to execute the micro-op. After execution, the micro-op results are stored in the ROB entry for that micro-op. This aspect of the Core design is clearly taken from the Yonah, Dothan and P6 architectures.
The biggest differences are not immediately visible on the diagrams above. Previous Intel architectures can only perform one branch prediction every two cycles, but Core can sustain one branch per cycle. The Athlon 64 can also perform one branch prediction per cycle.
Another impressive area is Core's SSE multimedia power. Three very powerful 128-bit SSE/SSE2/SSE3 units are available, and two of them are symmetric. Core will outperform the Athlon 64 vastly when it comes to 128-bit SSE2/3 processing.
On K8, 128-bit SSE instructions are decoded into two separate 64-bit instructions. Each Athlon 64 SSE unit can only do one 64-bit instruction at a time, so the Core architecture has essentially at least 2 times the processing power here. With 64-bit FP, Core can do 4 Double Precision FP calculations per cycle, while the Athlon 64 can do 3.
When it comes to integer execution resources, the Core architecture is an improvement over the Pentium 4 and Dothan CPUs, and is at the same level (if we only look at the number of execution units) as the Athlon 64. The Athlon 64 seems to have a small advantage when it comes to calculating addresses: it has 3 AGU compared to Core's 2. This could give the Athlon 64 an advantage in some less common integer workloads such as decrypting algorithms. The deeper, more flexible (Memory disambiguation, see further) out of order buffers and bigger, faster L2-cache of the Core should negate this small advantage in most integer workloads.








87 Comments
View All Comments
thestain - Friday, May 5, 2006 - link
Larger Cache and an extra decoder were bound to help Conroe in the small and simple tesing done by most benchmarks.But, what about applications that are a bit larger than Conroe's cache size or those that are complex causing the simple decoders to not be able to be used that much while placing the single complex decoder on the Conroe into short supply?
Mike
IntelUser2000 - Friday, May 5, 2006 - link
LOL. You crack me up. Go see how much doubling of L2 caches help to increase performance. I guess the last 5 years of Netburst screwed people's mental abilities. Sure the caches will help Conroe, but if the CPU doesn't really need the extra cache, then it will be a waste. Kinda like how doubling L2 caches on Pentium D doesn't help a lot. Kinda like how doubling L2 caches on Athlon 64's don't help either. It's why Semprons excel.
About decoders. Guess you are still in the old ages where one of the reasons K7 was better than P6 was because it has the ability to decode complex instructions in all decoders. If you read about Conroe, more of the instructions that USED to go to the complex decoders can now go to the simple decoders.
And which benchmark would that be.
Guess there is gonna be a lot of AMD fanboys that are gonna cry when Conroe is shown.
stopkidding - Tuesday, May 2, 2006 - link
Did anyone notice that this comment thread is virtually free of the usual "Intel-this, AMD-that" comments that usually are seen on this site. The "fanbois" have nothing to bitch about as their little brains can't comprehend whats written in this article! :-)Reynod - Wednesday, May 3, 2006 - link
Which is a sigh of relief I must say. I can swallow hard facts and interpret code ... my 4400+ looks like going in as my new server box ... and my next gaming box looks like being an OC'd Conroe. I just won't buy an Intel Mobo ... heh heh.mino - Tuesday, May 2, 2006 - link
IMHO not, the article is extremely well written AND there are NO benchmarks => Intelman is happy from the text; AMD-man is hoping the real numbere won't be so bad...On topic, article is written in a very good style for general public.
On thing I'am afraid of is the moment code is optimized for Core, any other irchitecture would take a performance hit. K8 the smallest one, PM/K7 the small one, P4/P6 the big one and all older plus C7 e pretty huge hits.
That bothers me.
Except that, AMD will live for a long time (Opteron alone would survive them for 5+ yrs.) and X2's will be finally cheaper. What else to pray for :)
Best regards.
mino - Tuesday, May 2, 2006 - link
addennum:"the article is extremely well written FOR GENERAL AT AUDIENCE"
Otherwise job well done Johan.
nullpointerus - Tuesday, May 2, 2006 - link
Right, but then why do they respond to the other articles?JustAnAverageGuy - Tuesday, May 2, 2006 - link
Another top notch article, as always, Johan- JaAG
dguy6789 - Tuesday, May 2, 2006 - link
Thank you for writing this article. You have cleared up a large quantity of questions that I had in relation to the Core architecture.Betwon - Tuesday, May 2, 2006 - link
sub eax,[edi+ebx+79]There are 3 registers used: eax, edi, ebx
For Core duo, it decodes to one fusion-micro-op.
In the reservation station (RS), only one entry is needed to be allocated. There are three registers spaces in one RS entry at least. And the results of address(edi+ebx+79) can be w rited back into the same position of one register in this RS entry.(A replace method)
For K7/K8, it decodes to one macro-op?
In the reservation station (RS), only one entry is needed to be allocated? There are three registers spaces in one RS entry?
It can take one entry in ROB.
But I don't believe AMD. It may take two entrys in RS, because there are only two registers spaces in one RS entry of K8. K8 hasn't three registers spaces in one RS entry.
K8's RS is up to 8X3 macro-op, but not means that one macro-op can always take one entry in the RS.
I say that I don't believe AMD.
Of course, Other people have on need to believe me too.