Out of Order execution: AMD versus Intel
To make this article more accessible and to make the differences between the AMD K8 and the new Intel Core architecture more clear, I tried to make both CPU diagrams in the same style. Here's the Core architecture overview: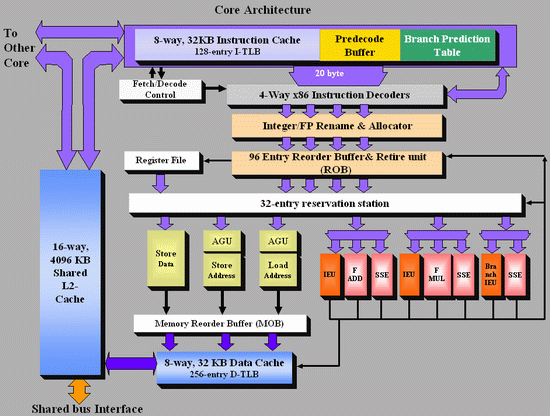
And here's the K8 architecture:
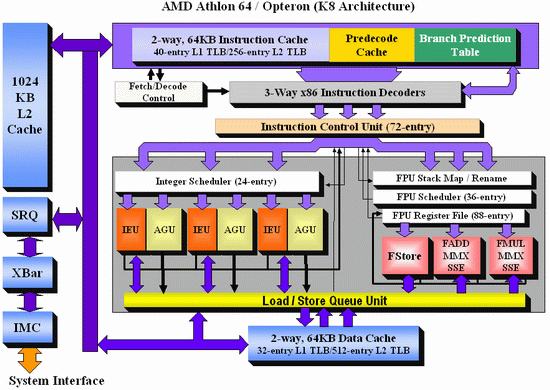
There are a few obvious differences: Core has bigger OoO buffers: the 96 entry ROB buffer is - also thanks to Macro-op fusion - quite a bit bigger than the 72 Entry Macro-op buffer of K8. The P6 architecture could order only 40 instructions, this was doubled to 80 in the P-M architecture (Banias, Dothan, Yonah), and now it's increased even further to 96 for the Core architecture. We've created a table which compares the most important architectural details of several current CPU families:
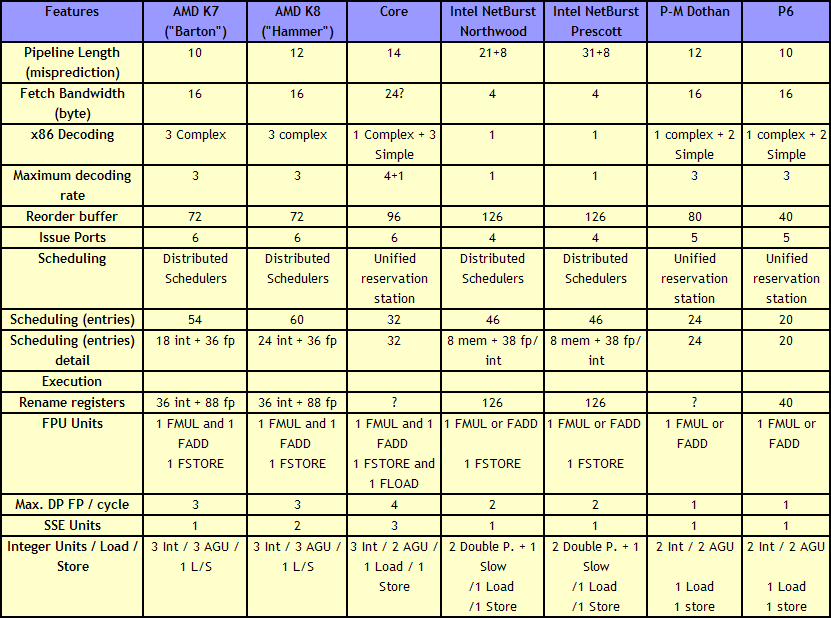 |
| Click to enlarge |
The Core architecture uses a central reservation station, while the Athlon uses distributed schedulers. The advantage of a central reservation station is that utilization is better, however distributed schedulers allow more entries. NetBurst also uses distributed schedulers.
Using a central reservation station is another clear example of how Core is in fact the "P8", the second big improvement of the P6 architecture. Just like the P6 architecture, it uses a Reservation Station (RS) and allocates a specific execution unit to execute the micro-op. After execution, the micro-op results are stored in the ROB entry for that micro-op. This aspect of the Core design is clearly taken from the Yonah, Dothan and P6 architectures.
The biggest differences are not immediately visible on the diagrams above. Previous Intel architectures can only perform one branch prediction every two cycles, but Core can sustain one branch per cycle. The Athlon 64 can also perform one branch prediction per cycle.
Another impressive area is Core's SSE multimedia power. Three very powerful 128-bit SSE/SSE2/SSE3 units are available, and two of them are symmetric. Core will outperform the Athlon 64 vastly when it comes to 128-bit SSE2/3 processing.
On K8, 128-bit SSE instructions are decoded into two separate 64-bit instructions. Each Athlon 64 SSE unit can only do one 64-bit instruction at a time, so the Core architecture has essentially at least 2 times the processing power here. With 64-bit FP, Core can do 4 Double Precision FP calculations per cycle, while the Athlon 64 can do 3.
When it comes to integer execution resources, the Core architecture is an improvement over the Pentium 4 and Dothan CPUs, and is at the same level (if we only look at the number of execution units) as the Athlon 64. The Athlon 64 seems to have a small advantage when it comes to calculating addresses: it has 3 AGU compared to Core's 2. This could give the Athlon 64 an advantage in some less common integer workloads such as decrypting algorithms. The deeper, more flexible (Memory disambiguation, see further) out of order buffers and bigger, faster L2-cache of the Core should negate this small advantage in most integer workloads.








87 Comments
View All Comments
Betwon - Wednesday, May 3, 2006 - link
If you really want to know what is the Intel's load reordering and memory misambiguation, I can tell you the facts:http://www.stanford.edu/~merez/papers/LoadSched_IS...">http://www.stanford.edu/~merez/papers/LoadSched_IS...
Speculation Techniques for Improving Load Related Instruction Scheduling 1999
Adi Yoaz, Mattan Erez, Ronny Ronen, and Stephan Jourdan -- From Intel's Haifa, they designed the Load/Store Unit of Core.
I had said that anandtech should study many things about CPU. Of course, I should study more things about CPU.
Betwon - Tuesday, May 2, 2006 - link
P6: sub [mem],eax decodes to three micro-opsCore duo: sub [mem],eax decodes to two micro-ops
K8: sub [mem],eax decodes to one macro-op
P6: sub eax,[mem] decodes to two micro-ops
Core duo: sub eax,[mem] decodes to one micro-op
K8: sub eax,[mem] decodes to one macro-op
Intel's micro-fusion is different with the K7/K8's macro-op.
P4 has 2X2 int ALU and 2 AGU.
K7/K8 has 3 int ALUand 3 AGU.
But Core duo has only 2 int ALU and 2 AGU.
The integer performance:
Core duo>K7/K8
Why?
Because Core duo's length of the depenency chain of the critical path is the shorest.
The most integer program asm codes can be thought as a high and thin tree of the depenency chain, (the longest depenency chain is called the critical path)
The critical path determines the performance. The length of the depenency chain of the critical path is the cycles needed to complete this critical path.
Core duo(2ALU/2AGU) spends less cycles than K7/K8(3ALU/3AGU) -- Because more INT funtions can not accelerate the true dependency atoms-operations.
The P-M/Core duo's special ability of anti true dependency atoms-operations is the real reason of it's INT outperformance, which is different with old P6(such as Pentium 3).
The most FP program asm codes can be thought as a boskage (there are many short depenency chains). The best ILP can be performed--The more FP FADD/FMUL funtions, the more performence.
Double the FP funtions or double the speed of half-speed FP functions is a good idea for the most FP programs.
But double INT funtions do not always enhence the INT preformence so greatly.
Conroe only has three ALUs and two AGUs, but not 4 ALU and 4AGU.
K7/K8 has three ALUs and three AGUs.
Betwon - Tuesday, May 2, 2006 - link
Sorry, I'm not one from a English-language nations. I just tell my idea with many spelling or syntax errors.funtions -- funtion units
I want to tell why Conroe with only 3ALU/2AGU has the INT outperformance. Core has the superexcellent ability to process the true dependency chains.(much much better than K8 3ALU/3AGU).
Even Core duo with 2ALU/2AGU has the INT outperformance(much better than K8 3ALU/3AGU).
The length of the depenency chain of the critical path
The true dependency atom-operations
Starglider - Monday, May 1, 2006 - link
A truly excellent article. I just have a couple of questions;It's clear that increasing FSB speed can reduce memory latency. However I'm not clear why lower CPU core speed will reduce absolute latency - sure it will reduce the number of CPU cycles that occur while waiting for memory, but how can it reduce the absolute delay?
You don't seem to have included inter-instruction latency in your comparison tables. I know this data can be hard to get hold of, but it's critical to the performance of highly serial code (e.g. the pi calculation benchmarks that seem to be so popular at the moment). Is there any chance it could be included?
Finally I'm wondering if Intel will revist some of the P4 clock speed enhancing tricks later on. Things like LVS and double pumped AUs would only have slowed down an already complex development process that Intel desperately needed to be completed quickly. But if AMD do come out with a new architecture that matches or exceeds Conroe on IPC, Intel might be able to respond quite quickly by bringing back some of their already well understood clock speed tricks to accelerate Conroe.
Makaveli - Monday, May 1, 2006 - link
You need to get away from thinking of increased clockspeed for extra performance, the future is multicore Cpu's and parellism.Starglider - Tuesday, May 2, 2006 - link
I write heavily multithreaded applications for a living, but sometimes there is just no substitute for fast serial execution; a lot of things just can't be parallelised. Serial execution speed is effectively IPC * clock rate, so yes increasing clock rate is still very helpful as long as IPC doesn't suffer.saratoga - Monday, May 1, 2006 - link
^^ Did you read the post you replied to? His point is valid.Lower clock speed is not going to improve memory latency. It may mean that latency is less painful, but if you took two core chips, one at 2GHz and the other at 3GHz, the absolute latency is roughly if not exactly the same for each. Though the cost of each ns of latency is 50% more dear on the 3GHz chip.
Spoonbender - Tuesday, May 2, 2006 - link
It would be more accurate to say that each cycle of latency is more dear on the 2ghz chip, wouldn't it? ;)What matters is how *long* the latency is, in ns. A ns latency is a ns, and it forces the cpu to wait exactly one ns, no matter its clock speed... :)
So yeah, definitely a valid point, and I wondered about that in the article as well.
saratoga - Wednesday, May 3, 2006 - link
No. Its 50% worse for the 3GHz chip (since the clock speed is 50% higer).
And one ns is how many clock cycles on a 2GHz chip? And how many of a 3GHz chip? Think this through . . .
Spoonbender - Wednesday, May 3, 2006 - link
No it isn't. They both waste *exactly* one ns of execution per, well, ns of latency. How many cycles they can cram into that ns is irrelevant.
[quote]
And one ns is how many clock cycles on a 2GHz chip? And how many of a 3GHz chip? Think this through . .
[/quote]
Yeah, of course, with 1 ns latency, a 3ghz chip will waste more clock cycles than a 2ghz chip, yes. That's obvious. But they will both lose exactly 1 ns worth of execution. That's what matters. Not the number of clock cycles.
If they both perform equally well, despite the clock speed difference, then adding 1 ns latency to both will have exactly the same impact on both. Yes, the 3ghz chip will lose more clock cycles, but the 2ghz will (if we stick with the assumption of similar performance), have a higher IPC, and so waste the same amount of actual work.
If you like, look at Athlon 64 and P4.
If both cpu's waste one clock cycle, then the A64 takes the biggest impact, because of its higher IPC.
If both cpu's waste one ns, it doesn't change anything. True, the P4 loses the biggest amount of cycles, but as I said before, the A64 loses more *per* cycle. The net result is that they both lose, wait for it, *one* nanosecond's worth of execution.