Smarter Prefetching and Caching
Making sure that the right instructions and data are ready for use in the caches in the "3 GHz and beyond" era is one of the most important tasks of the architectural engineer. This helps to ensure performance increases as clockspeeds get pushed higher; otherwise, higher CPU clockspeeds will simply result in the processor spending more time waiting for data. This technique of priming the caches is knows as Prefetching; however, the current hardware prefetching algorithms don't always lead to success. There are quite a few cases where they can actually lower performance, especially in bandwidth sensitive applications.The Core architecture prefetching is without any doubt superior to what can be found in the Athlon 64 and Pentium 4. There are no less than three prefetchers - two data, one instruction - in each core, plus two prefetchers for the L2-cache. With eight prefetchers active in one dual-core Core CPU, all those prefetchers could easily get in the way of the "demand" bandwidth - the bandwidth which is needed by the load operations of the running program. In order to avoid this bottleneck, the prefetch monitor of the Core CPUs always give priority to the demand bandwidth; the prefetchers will never steal too much bandwidth away from the running program.
There is more. The data prefetch needs to perform tag lookups (tags = index of cache) in the caches frequently. To avoid this resulting in higher latency for the "normal" (caused by the program running) tag lookups, the data prefetch uses the store port for the tag lookup. If you remember, loads happen about twice as often as stores. This means the store port is used only half as much as the load port and it make sense to use that port for tag lookup by the prefetchers. Note also that stores are not critical for system performance in most cases -- once the data is "written" the processor can go on about its business. The cache/memory subsystem is in charge of replicating the data down to main memory, and as long as this happens eventually, everything works fine.
The cache system of the Core CPU is also very impressive. A massive 4 MB L2-cache is shared between the two cores and is accessed in only 12 to 14 cycles. Each core also has a 3 cycle 32 KB Instruction cache and a 32 KB data cache at its disposal. Note that the "Trace Cache" of NetBurst has been left behind with the return to shorter pipelines; the NetBurst Trace Cache basically functions as an instruction cache for pre-decoded instructions, and while this was apparently helpful for the long pipeline of NetBurst, Intel has apparently determined that a traditional L1 caching scheme makes more sense for Core.
Cache Architecture Overview
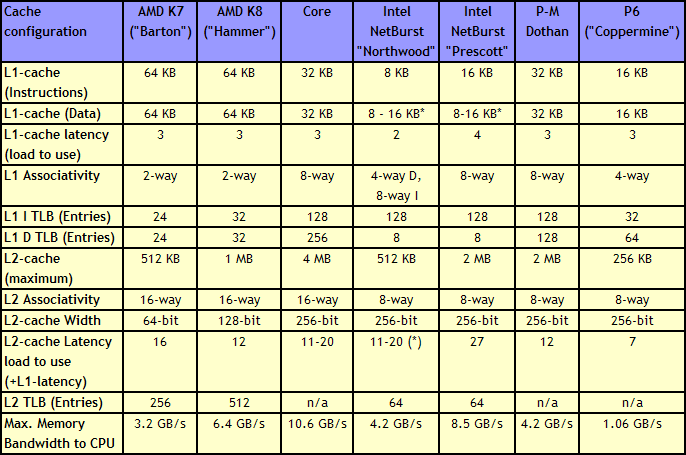 |
| Click to enlarge |
Just a quick look at the numbers in the above table make it clear that the memory subsystem of the Core architecture is impressive. It has twice as much L2 cache as current dual-core CPUs (the same amount as Presler), but the cache is still accessible with low latency. The shared L2 cache also allows one core to use more than 2MB of cache if necessary. Both L1 and L2 cache are accessed via a 256-bit wide bus, allowing the caches to deliver massive bandwidth to the core.
Core versus Hammer: Memory subsystem
Core's most important competitor, the Hammer ("K8") architecture, has two small but noteworthy advantages. The first is its bigger 2 x 64 KB L1 cache. This is only a small advantage as an 8-way 32 KB cache will have a hit rate close to that of a 2-way 64 KB cache.The second and more important advantage is the on die memory controller, which lowers the latency to the memory considerably. However, the lower clockspeeds of the Core CPUs (relative to NetBurst) and the faster FSB also lower latency significantly. With the numbers available to us now, we have reason to believe that the Athlon 64 X2's latency advantage will shrink to only 15 to 20%. For comparison, the memory subsystem of the Pentium 4 was almost twice as slow as the Athlon 64 (80-90 ns versus 45-50 ns).
However, those two small advantages are likely negated by all the other memory subsystem metrics. The Core CPUs have much bigger caches and much smarter prefetching than the competition. The Core architecture's L1 cache delivers about twice as much bandwidth (Measured by ScienceMark), while it's L2-cache is about 2.5 times faster than the Athlon 64/Opteron one.








87 Comments
View All Comments
JohanAnandtech - Monday, May 1, 2006 - link
Thanks.The current Core Papers are pretty poor IMHO.
Best sources of info:
- Jack Doweck
- IDF's presentations
- David Kanter's article at RWT (going to add that link in the references)
Orbs - Monday, May 1, 2006 - link
I never studied chip design but even with my limited assembly knowledge I was able to follow this article. Very technical, very informative, and helps explain some of the insane benchmark results from Conroe's preview earlier this year.It will be interesting to see how Conroe/Merom perform when finalized, how they compare to final AM2 CPUs (especially higher clocked AM2 CPUs) and what AMD counters with in '07.
JohanAnandtech - Monday, May 1, 2006 - link
"I never studied chip design but even with my limited assembly knowledge I was able to follow this article"Very happy to read that.
At this point there is not enough info on what AMD has in store, so I left that out. However, better load reordering (besides the announced extra FP power) seems a minimum for the next AMD micro-arch.
at80eighty - Monday, May 1, 2006 - link
Been a while since we've seen you around Johan - nice read btwAvalon - Monday, May 1, 2006 - link
Wow, very nice read. Thanks a ton!owned66 - Monday, February 25, 2013 - link
soo many AMD fan boys back thenhere is 2013 they dont exist anymore
lollichop - Sunday, February 26, 2017 - link
Fast forward 11 years. It's 2017. After a big decline, AMD is back in the game with Ryzen.