Introduction & Manufacturing
AMD held its spring Analyst Day on Thursday, and we were able to sit down and enjoy the webcast. While we fully expected to learn about AMD's next CPU architecture, K8L, we were pleasantly surprised to find a few unexpected extras. The event covered a huge swath of the computing industry in a manner that went just deep enough to leave us screaming for more. Unfortunately, we don't have all the answers we wanted today, but we do have some good ideas about what we'll be seeing in the near future about AMD's upcoming technology.
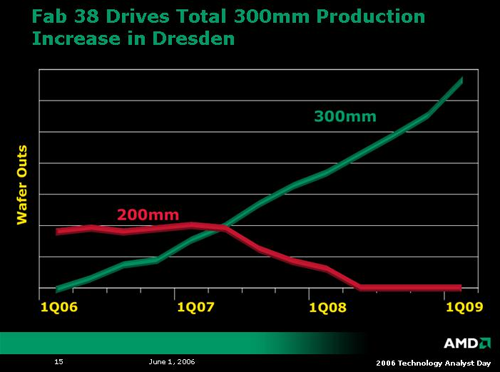
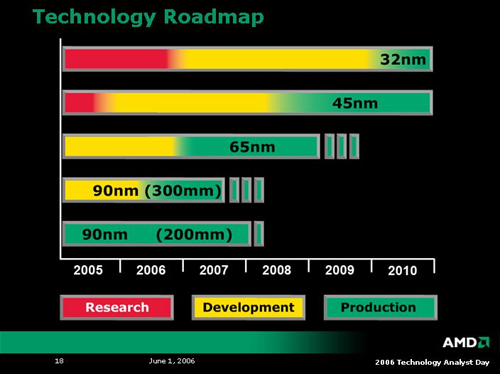
As could be expected, the day started off with an overview of AMD's fabrication strategies. In the near term, AMD is transitioning from 200mm wafers for its 90nm SOI process to 300mm wafers. This will help serve to get AMD up to speed with 300mm wafer before volume production of 65nm devices begins. As 200mm wafer production is phased out, 65nm processes will be ramping into full swing. AMD plans on an aggressive schedule for transitioning to the smaller process technology, and an even more aggressive schedule for pushing out 45nm technology after this product cycle. As of now, AMD plans to introduce production 45nm silicon only 18 months after 65nm hardware hits the market.
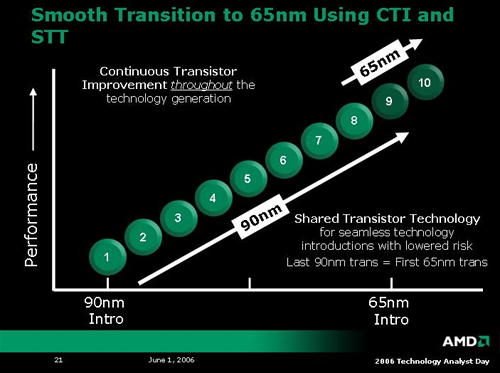
In moving to 65nm, AMD has adopted a strategy of constant improvement of its current transistor technology to ensure a smooth transition. The last generation 90nm parts will overlap the first generation 65nm parts, as many of the key features of their structures will be shared. AMD calls this Shared Transistor Technology and Continuous Transistor Improvement. As small improvements are made over the entire life cycle of a process, the final transition from one type of process to another is made much easier.

After AMD showed off a bunch of slides about how their fab is better than your fab, they started to touch on a few topics that really get our groove on: platform architecture. AMD introduced three new platform initiatives, and talked a little bit about their K8L architecture. First we'll talk about the direction AMD is moving with their platform technology.
AMD held its spring Analyst Day on Thursday, and we were able to sit down and enjoy the webcast. While we fully expected to learn about AMD's next CPU architecture, K8L, we were pleasantly surprised to find a few unexpected extras. The event covered a huge swath of the computing industry in a manner that went just deep enough to leave us screaming for more. Unfortunately, we don't have all the answers we wanted today, but we do have some good ideas about what we'll be seeing in the near future about AMD's upcoming technology.
As could be expected, the day started off with an overview of AMD's fabrication strategies. In the near term, AMD is transitioning from 200mm wafers for its 90nm SOI process to 300mm wafers. This will help serve to get AMD up to speed with 300mm wafer before volume production of 65nm devices begins. As 200mm wafer production is phased out, 65nm processes will be ramping into full swing. AMD plans on an aggressive schedule for transitioning to the smaller process technology, and an even more aggressive schedule for pushing out 45nm technology after this product cycle. As of now, AMD plans to introduce production 45nm silicon only 18 months after 65nm hardware hits the market.
In moving to 65nm, AMD has adopted a strategy of constant improvement of its current transistor technology to ensure a smooth transition. The last generation 90nm parts will overlap the first generation 65nm parts, as many of the key features of their structures will be shared. AMD calls this Shared Transistor Technology and Continuous Transistor Improvement. As small improvements are made over the entire life cycle of a process, the final transition from one type of process to another is made much easier.
After AMD showed off a bunch of slides about how their fab is better than your fab, they started to touch on a few topics that really get our groove on: platform architecture. AMD introduced three new platform initiatives, and talked a little bit about their K8L architecture. First we'll talk about the direction AMD is moving with their platform technology.








40 Comments
View All Comments
peternelson - Saturday, June 3, 2006 - link
High end pcie cards are available if you look for them
eg Areca 8 sata II onto 8x pci express
eg Myrinet 10 gigabit ethernet onto 8x pci express
Plenty of other examples.
Also, witness the highend server boards many are now offering pcie as an option to the former server standard pci-x.
PCIE is here to stay and is a must for anyone interested in a performance system.
There is a direct mapping of pcie onto Hypertransport.
There is already fast networking available on an HTX card.
lopri - Friday, June 2, 2006 - link
Correction: ..video card.. transfers data via PCI Express..;)
saratoga - Friday, June 2, 2006 - link
I'm a little confused. IIRC Core2 can do 2x 128 bit operations, each of which can be an add or multiply, but only one of which can be a load. AMD is restricting the actual operations to just 1 add and 1 multiply, but is removing the restriction on loads? So they'll be better able to feed the vector units then Intel, but have less flexibility once they've loaded?
That doesn't make a whole lot of sense to me. I'd think if their SSE implementation was less agressive, they would not have added more load units to feed it. Has AMD confirmed that there are only 1 add and 1 mult unit? Or is this a case of Intel designing a nice backend and not providing the front end resources to keep it fed?
mino - Friday, June 2, 2006 - link
Well, you're kinda right and wrong at the same time:)However intel's C2 frontend(from L2 up) is far superior to AMD's. And was such since Banias. Also intel's backend(execution units) is now on par but only recently Yonah and older were inferior to AMD's brute force 3-issue backend.
AMD has kinda ingeniously hidden poor backend by IMC however for streamed(desktop) pseudo-random loads intel's huge cache structures mitigated this so they are forced to improve frontend(hard to do) and do some backend optimizations(easy) on the way. Well, they kinda knew they will have to do this since the 90's, they have just chosen to implement IMC and cater to the core itself in the next iteration.
On the 2load units - without them the maxFLOPS would be n, real one x. With them(load units are relatively simple and low power compared to FPU's) they've got MmaxFLOPS around 2n AND real achievable one(IMHO) in the 1.2x~1.5x range. Pretty good ROI for the one added load unit.
saratoga - Saturday, June 3, 2006 - link
Could you explain how?
No it wouldn't. CPUs have registers, so the number of load units has nothing to do with FLOPs. You could have just one load unit and still sustain an arbitrary number of FLOPs, provided you didn't mind using the same registers over and over again, which I suppose could be the case if you're doing an iterative approximation of a value.
I don't think loads count as FLOPs, even if you're loading things to be used in FP operations, so having more load units doesn't increase max FLOPs.
mino - Friday, June 2, 2006 - link
Sory for the english, grammar wasn't my friend :)DigitalFreak - Friday, June 2, 2006 - link
The smartest thing AMD ever did was create HyperTransport. There are so many cool uses for it! Intel, on the other hand, still insists on using their proprietary solutions.DerekWilson - Friday, June 2, 2006 - link
HyperTransport was created by an open consortium.But you do have to remember that AMD implimented a propreitary coherent HT for use in SMP systems. They haven't always been open, even if their method was implimented on top of an open standard.
I do agree that general use of HyperTransport makes I/O much easier on many levels, and was a very good move for AMD. And now that they are opening up cHT, some really cool things can happen -- if the industry is ready. :-)
Viditor - Saturday, June 3, 2006 - link
Actually, it was created by AMD, it was developed by an open consortium.
However coherent HT is still (at least until now) proprietary AMD...
Viditor - Saturday, June 3, 2006 - link
Doh! I need to read first, post second...already asked and answered. Sorry...