The GPU Advances: ATI's Stream Processing & Folding@Home
by Ryan Smith on September 30, 2006 8:00 PM EST- Posted in
- GPUs
Enter the GPU
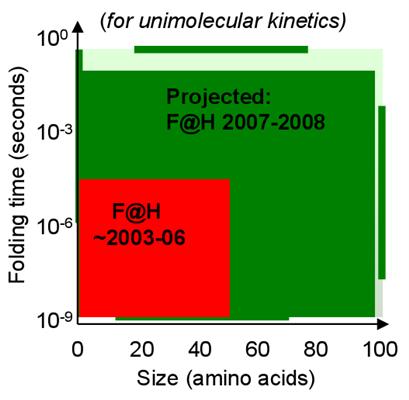
Modern GPUs such as the R580 core powering ATI's X19xx series have upwards of 48 pixel shading units, designed to do exactly what the Folding@Home team requires. With help from ATI, the Folding@Home team has created a version of their client that can utilize ATI's X19xx GPUs with very impressive results. While we do not have the client in our hands quite yet, as it will not be released until Monday, the Folding@Home team is saying that the GPU-accelerated client is 20 to 40 times faster than their clients just using the CPU. Once we have the client in our hands, we'll put this to the test, but even a fraction of this number would represent a massive speedup.
With this kind of speedup, the Folding@Home research group is looking to finally be able to run simulations involving longer folding periods and more complex proteins that they couldn't run before, allowing them to research new proteins that were previously inaccessible. This implementation also allows them to finally do some research on their own, without requiring the entire world's help, by building a cluster of (relatively) cheap video cards to do research, something they've never been able to do before.
Unfortunately for home users, for the time being, the number of those who can help out by donating their GPU resources is rather limited. The first beta client to be released on Monday only works on ATI GPUs, and even then only works on single X19xx cards. The research group has indicated that they are hoping to expand this to CrossFire-enabled platforms soon, along with less-powerful ATI cards.
The situation for NVIDIA users however isn't as rosy, as while the research group would like to expand this to use the latest GeForce cards, their current attempts at implementing GPU-accelerated processing on those cards has shown that NVIDIA's cards are too slow compared to ATI's to be used. Whether this is due to a subtle architectural difference between the two, or if it's a result of ATI's greater emphasis on pixel shading with this generation of cards as compared to NVIDIA we're not sure, but Folding@Home won't be coming to NVIDIA cards as long as the research group can't solve the performance problem.
Conclusion
The Folding@Home project is the first of what ATI is hoping will be many projects and applications, both academic and commercial, that will be able to tap the power of GPUs. Given the results showcased by the Folding@Home project, the impact on the applications that would work well on a GPU could be huge. In the future we hope to be testing technologies such as GPU-accelerated physics processing for which both ATI and NVIDIA have promised support, and other yet to be announced applications that utilize stream processing techniques.
It's been a longer wait than we were hoping for, but we're finally seeing the power of the GPU unleashed as was promised so long ago, starting with Folding@Home. As GPUs continue to grow in abilities and power, it should come as no surprise that ATI, NVIDIA, and their CPU-producing counterparts are looking at how to better connect GPUs and other such coprocessors to the CPU in order to further enable this kind of processing and boost its performance. As we see AMD's Torrenza technology and Intel's competing Geneseo technology implemented in computer designs, we'll no doubt see more applications make use of the GPU, in what could be one of the biggest-single performance improvements in years. The GPU is not just for graphics any more.
As for our readers interested in trying out the Folding@Home research group's efforts in GPU acceleration and contributing towards understanding and finding a cure for Alzheimer's, the first GPU beta client is scheduled to be released on Monday. For more information on Folding@Home or how to use the client once it does come out, our Team AnandTech members over in our Distributed Computing forum will be more than happy to give a helping hand.
Modern GPUs such as the R580 core powering ATI's X19xx series have upwards of 48 pixel shading units, designed to do exactly what the Folding@Home team requires. With help from ATI, the Folding@Home team has created a version of their client that can utilize ATI's X19xx GPUs with very impressive results. While we do not have the client in our hands quite yet, as it will not be released until Monday, the Folding@Home team is saying that the GPU-accelerated client is 20 to 40 times faster than their clients just using the CPU. Once we have the client in our hands, we'll put this to the test, but even a fraction of this number would represent a massive speedup.
 |
| Click to enlarge |
With this kind of speedup, the Folding@Home research group is looking to finally be able to run simulations involving longer folding periods and more complex proteins that they couldn't run before, allowing them to research new proteins that were previously inaccessible. This implementation also allows them to finally do some research on their own, without requiring the entire world's help, by building a cluster of (relatively) cheap video cards to do research, something they've never been able to do before.
Unfortunately for home users, for the time being, the number of those who can help out by donating their GPU resources is rather limited. The first beta client to be released on Monday only works on ATI GPUs, and even then only works on single X19xx cards. The research group has indicated that they are hoping to expand this to CrossFire-enabled platforms soon, along with less-powerful ATI cards.
The situation for NVIDIA users however isn't as rosy, as while the research group would like to expand this to use the latest GeForce cards, their current attempts at implementing GPU-accelerated processing on those cards has shown that NVIDIA's cards are too slow compared to ATI's to be used. Whether this is due to a subtle architectural difference between the two, or if it's a result of ATI's greater emphasis on pixel shading with this generation of cards as compared to NVIDIA we're not sure, but Folding@Home won't be coming to NVIDIA cards as long as the research group can't solve the performance problem.
Conclusion
The Folding@Home project is the first of what ATI is hoping will be many projects and applications, both academic and commercial, that will be able to tap the power of GPUs. Given the results showcased by the Folding@Home project, the impact on the applications that would work well on a GPU could be huge. In the future we hope to be testing technologies such as GPU-accelerated physics processing for which both ATI and NVIDIA have promised support, and other yet to be announced applications that utilize stream processing techniques.
It's been a longer wait than we were hoping for, but we're finally seeing the power of the GPU unleashed as was promised so long ago, starting with Folding@Home. As GPUs continue to grow in abilities and power, it should come as no surprise that ATI, NVIDIA, and their CPU-producing counterparts are looking at how to better connect GPUs and other such coprocessors to the CPU in order to further enable this kind of processing and boost its performance. As we see AMD's Torrenza technology and Intel's competing Geneseo technology implemented in computer designs, we'll no doubt see more applications make use of the GPU, in what could be one of the biggest-single performance improvements in years. The GPU is not just for graphics any more.
As for our readers interested in trying out the Folding@Home research group's efforts in GPU acceleration and contributing towards understanding and finding a cure for Alzheimer's, the first GPU beta client is scheduled to be released on Monday. For more information on Folding@Home or how to use the client once it does come out, our Team AnandTech members over in our Distributed Computing forum will be more than happy to give a helping hand.








43 Comments
View All Comments
photoguy99 - Sunday, October 1, 2006 - link
The folding team just hasn't designed their architecture efficiently for parallelism within a system.No doubt they are brilliant computational biologists, but it's simply an oxymoron to claim a system can scale well using thousands of systems but not with the cores within those systems - Nonsense.
In fact I challenge anyone from their coding team to explain this contradiction.
Now if they say look, we're busy, we just haven't had time to optimize the architecture for multi-core yet, then that makes perfect sense. But to say inherently the problem doesn't lend itself to that is not right.
JarredWalton - Sunday, October 1, 2006 - link
Not at all true! See above comments, but data dependency is a key. They know the starting point, but beyond that they don't know anything. So they might generate 100,000 (or more) starting points. There's 100K WUs out there. They can't even start the second sequence of any of those points until the first point is complete.Think of it within a core: They can split up a task into several (or hundreds) of pieces only if each piece is fully independent. It's not like searching for primes where scanning from 2^100000 to 2^100001 is totally unrelated to what happened in 2^99999 to 2^100000. Here, what happens at stage x of Project 2126 (Run 51, Clone 9, Gen 7) absolutely determins where stage x+1 of Project: 2126 (Run 51, Clone 9, Gen 7) begins. A separate task of Project: 2126 (Run 51, Clone 9, Gen 6) or whatever can be running, but the results there have nothing to do with Project: 2126 (Run 51, Clone 9, Gen 7).
photoguy99 - Monday, October 2, 2006 - link
Jared, I respectfully submit that you are not correct.Think of it this way - what is the algorithmic difference between submiting jobs to distributed PCs vs. distributed processes within a PC?
Multiple processes within a PC could operate indepedently and easily take advantage of the multi-core parallelism. A master UI process could manage the sub processes on the machine so the that user would not even require special setup by the user.
I'm telling you the problem with leveraging multi-core is not inherent to the folding problem, it's just a limitation of how they've designed their architecture.
Again not to take away credit from all the goodness they have achieved, but if you think about it this is really indisputable. I'm sure their developers would agree.
JarredWalton - Monday, October 2, 2006 - link
Are we talking about *can* they get some advantage from multiple cores with different code, or are we talking about gaining a nearly 2X performance boost? I would agree that there is room for them to use more than one core, but I would guess the benefit will be more like a 50% speedup.Right now, running two instances of FAH nearly doubles throughput, but no individual piece is completed faster. They could build in support for executing multiple cores without user intervention, but that's not a big deal since you can already do that on your own. Their UI could definitely be improved. The difficulty is that they aren't able to crank out individual pieces faster; they can get more pieces done, but if there's a time sensitive project they can't explore it faster. For example, what if they come on a particular folding sequence that seems promising, and they'd like to investigate it further with 100K slices covering several seconds (or whatever). If piece one determines piece 2, and 2 determimes 3... well, they're stuck with a total time to calculate 100K segments that would be in the range of thousands of years (assuming a day or two per piece).
Anyway, there are tasks which are extremely difficult to thread, though I wouldn't expect this to be one. Threading and threading really well aren't the same, though. Four years from now, if they get octal core CPUs, that increases the total number of cores people can process, but they wouldn't be able to look at any longer sequences than today if CPUs are still at the same clockspeed. (GPUs doing 40X faster means they could look at 40X more length/complexity.)
Anyway, without low level access to their code and an understanding of the algorithms they're using, the simple truth is that neither of us can say for sure what they can or can't get from multithreading. Then there's the whole manpower problem - is it more beneficial to work on multithread, or to work on something else? Obviously, so far they have done "something else". :)
smitty3268 - Monday, October 2, 2006 - link
Looking at their website, they are working on a multithreaded core which would take advantage of smp systems. Regardless of how well that turns out, a 40x increase is not going to happen until we get > 40 cores in a cpu, so this GPU client is still a very big deal.I understand what you mean about data dependence and not being able to move on to more involved simulations due to time factors of individual work units, but it seems like this would be fairly easy to solve by simply splitting the work units in half or in quarters, etc. This could definitely be difficult to do, though, depending on how their software has been designed. Perhaps they would have to completely rewrite their software and it isn't worth the trouble.
JarredWalton - Tuesday, October 3, 2006 - link
I don't think they can split a WU in half, though, or whatever. Best they can do would be to split off a computation so that, i.e. atoms 1-5000 are solved at each stage on core 1 and 5001-10000 are on core 2. You still come back to the determination of the "trajectory". If you start at A and you want to know where you end up, the only way to know is to compute each point on the path. You can't just break that calculation into A-->C and then C-->B with C being halfway.I know the Pande people are working on a lot of stuff right now, so GPUs, PS3, SMP, etc. are all being explored to varying extents.
icarus4586 - Wednesday, October 4, 2006 - link
The reason that modern GPUs are so powerful is that they have many parallel processing pipelines, which is only a little different than saying that they have many processing cores. Even the diagram given in this article is titled: "Modern GPU: 16-48 Multi-threaded cores." If the F@H algorithm can be optimized to use the parallelism that exists within modern GPUs, it should also be optimizeable for the parallelism of multi-core CPUs.smitty3268 - Sunday, October 1, 2006 - link
I still don't really see what the actual problem is, but I'll certainly take their word for it. Maybe if I ever get a degree in biochemistry I'll try and figure out what's going on :)
Thanks for the info. I think I'll go ahead and install F@H. It's something I've occasionally meant to do but I keep forgetting about it.
Furen - Sunday, October 1, 2006 - link
I think it's about data dependency. Let's say you start 2000 processes on different PCs and run them for 1 unit time. The result from this is 2000 processes at 1 unit time, not 1 process at 2000 units time, which is probably what you'd prefer. Having a massive speed up on a single node means that that node can push a single "calculation" farther along. I'd guess that the client itself is not multithreaded because of the threading overhead, it may not be worth the effort to optimize heavily for a dual-core speed up since the overhead will take a chunk out of that but a 40x speed up is another thing altogether.JarredWalton - Sunday, October 1, 2006 - link
The way FAH currently works is that pieces of a similation are distributed; some will "fail" (i.e. fold improperly or hit a dead end) early, others will go for a long time. So they're trying to simulate the whole folding sequence under a large set of variables (temperatures, environment, acid/base, whatever), and some will end earlier than others. Eventually, they reach the stage where most of the sequences are in progress, and new work units are generated as old WUs are returned. That's where the problem comes.If we were still scaling to higher clock speed, they could increase the size/complexity of simulations and still get WUs back in 1-5 days on average. If you add multiple cores at the same clock speed as earlier CPUs (i.e. X2 3800+ is the same as two Athlon 64 3200+ CPUs), you can do twice as many WUs at a time, but you're still waiting the same amount of time for results that may be important for future WU creation.
Basically, Pande Group/Stanford has simulations that they'd like to run that might take months on current high-end CPUs, and then they don't know how fast each person is really crunching away - that's why some WUs have a higher priority. Now they can do those on an X1900 and get the results in a couple days, which makes the work a lot more feasible to conduct.
That's one scenario, at least.