NVIDIA's 1.4 Billion Transistor GPU: GT200 Arrives as the GeForce GTX 280 & 260
by Anand Lal Shimpi & Derek Wilson on June 16, 2008 9:00 AM EST- Posted in
- GPUs
Overclocked and 4GB of GDDR3 per Card: Tesla 10P
Now let's say that you want to get some real work done with NVIDIA's GT200 GPU but that 1.4 billion transistor chip just isn't enough. NVIDIA does have an answer for you, in the form of an overclocked GT200 with the 240 SPs running at 1.5GHz (up from 1.3GHz in the GTX 280) and with a full 4GB of GDDR3 memory on-board.

Today NVIDIA is also announcing their next generation Tesla product based on GT200 (called a T10P when used on Tesla for some reason). The workstation graphics guys will have to wait a while for a GT200 Quadro unfortunately. This new Tesla is similar to the older model in that it has much more RAM and no IO ports. The server version is also clocked higher than the desktop part because fan noise isn't an issue and data centers have lower ambient temperatures than some corner of an office under a desk.

The Tesla C1060 has an entire 4GB of RAM on board. This is obviously very large and will do well to accomodate the large scale scientific computing apps it is targeted at. This card is designed for use in workstations and is the little brother to the new monster server that is also being announced today.

The Tesla S1070 is a 1U server containing essentially 4 C1060 cards for a total of 16GBs of RAM on 960 SPs. This server, like the older version, connects to a server via a PCIe cable and is designed to run code written for CUDA at incredible speeds. With 120 double precision IEEE 754r floating point units in combination with the 960 single precision IEEE 754 units, this server is a viable option for many more projects than the previous Tesla hardware which was only capable of single precision floating point.
Though we don't have an application to benchmark the double precision floating point hardware on GT200 yet, NVIDIA states that a GT200 can roughly match an 8 core Xeon system in DP performance. This would put the S1070 on par with a 32 way Xeon setup at less than 700W. Needless to say, single precision code runs much much faster and can outpace hundreds of traditional CPUs in parallel.
While these servers are expensive (though we don't have pricing), they are cheap compared to the alternatives currently out there. The fact that CUDA code can be implemented and tested on any of the 70 million NVIDIA G80+ GPUs currently in people's hands means that developer already have a platform to test and debug code on before committing to the Tesla solution. On top of that, schools are beginning to adopt CUDA as a teaching tool for parallel computing. As CUDA gains acceptance and the benefits of GPU computing are realized, more and more major markets will take interest.
The graphics card is no longer a toy. The combination of CUDA's academic acceptance as a teaching tool and the availability of 64-bit floating point in GT200 make GPUs a mission critical computing tool that will act as a truly disruptive technology. Not only will many major markets that depend on high performance floating-point processing realize this, but every consumer with an NVIDIA graphics card will be able to take advantage of hundreds of gigaflops of performance from CUDA based consumer applications.
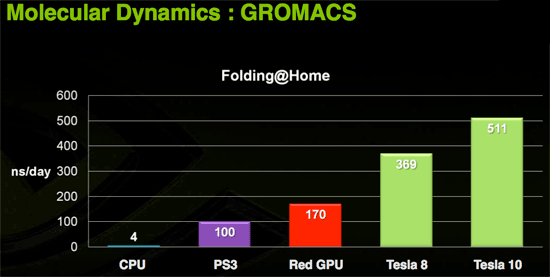
Today we have folding@home and soon we'll have Elemental's transcoder. Imagine the audio and video processing capabilities of a PC if the GPU were actively used in software like ProTools and Premier. Open source programs could easily best the processing capabilities of many solutions with dedicated hardware for these types of applications.
Of course, the major limiter to the adoption of this technology is that it is vendor specific. If NVIDIA put the time in (or enlisted help) to make CUDA an ANSI or ISO standard extention to a programming language, we would could really start to get excited. Beyond that, the holy grail would be a unification of virtualized instruction sets creating a standard low level "assembly" interface for GPU computing allowing CUDA to compile to one target and run on any graphics card. Sort of an x86 for massively parallel work.
Right now CUDA compiles to PTX, NVIDIA's virtual instruction set, and there is no reason someone couldn't write a CUDA compiler to target AMD's equivalent CAL (or even to develop a PTX to CAL wrapper that allowed AMD GPUs to run compiled CUDA code). Unfortunately, NVIDIA doesn't want to invest money and resources in extending functionality to AMD and AMD doesn't want to invest money and resources into bolstering an NVIDIA owned technology (that could theoretically radically change to cripple AMD's hardware support in future versions). While standards and cooperation are a great idea, the competition in this market is such that neither NVIDIA nor AMD are looking to take a chance on benefiting the consumer if there is any risk of strenthening the competition (even in spite of weakening the industry).








108 Comments
View All Comments
strikeback03 - Tuesday, June 17, 2008 - link
So are you blaming nvidia for games that require powerful hardware, or just for enabling developers to write those games by making powerful hardware?InquiryZ - Monday, June 16, 2008 - link
Was AC tested with or without the patch? (the patch removes a lot of performance on the ATi cards..)DerekWilson - Monday, June 16, 2008 - link
the patch only affects performance with aa enabled.since the game only allows aa at up to 1680x1050, we tested without aa.
we also tested with the patch installed.
PrinceGaz - Monday, June 16, 2008 - link
nVidia say they're not saying exactly what GT200 can and cannot do to prevent AMD bribing game developers to use DX10.1 features GT200 does not support, but you mention that"It's useful to point out that, in spite of the fact that NVIDIA doesn't support DX10.1 and DX10 offers no caps bits, NVIDIA does enable developers to query their driver on support for a feature. This is how they can support multisample readback and any other DX10.1 feature that they chose to expose in this manner."
Now whilst it is driver dependent and additional features could be enabled (or disabled) in later drivers, it seems to me that all AMD or anyone else would have to do is go through the whole list of DX10.1 features and query the driver about each one. Voila- an accurate list of what is and isn't supported, at least with that driver.
DerekWilson - Monday, June 16, 2008 - link
the problem is that they don't expose all the features they are capable of supporting. they won't mind if AMD gets some devs on board with something that they don't currently support but that they can enable support for if they need to.what they don't want is for AMD to find out what they are incapable of supporting in any reasonable way. they don't want AMD to know what they won't be able to expose via the driver to developers.
knowing what they already expose to devs is one thing, but knowing what the hardware can actually do is not something nvidia is interested in shareing.
emboss - Monday, June 16, 2008 - link
Well, yes and no. The G80 is capable of more than what is implemented in the driver, and also some of the implemented driver features are actually not natively implemented in the hardware. I assume the GT200 is the same. They only implement the bits that are actually being used, and emulate the operations that are not natively supported. If a game comes along that needs a particular feature, and the game is high-profile enough for NV to care, NV will implement it in the driver (either in hardware if it is capable of it, or emulated if it's not).What they don't want to say is what the hardware is actually capable of. Of course, ATI can still get a reasonably good idea by looking at the pattern of performance anomalies and deducing which operations are emulated, so it's still just stupid paranoia that hurts developers.
B3an - Monday, June 16, 2008 - link
@ Derek - I'd really appreciate this if you could reply...Games are tested at 2560x1600 in these benchmarks with the 9800GX2, and some games are even playable.
Now when i do this with my GX2 at this res, a lot of the time even the menu screen is a slide show (often under 10FPS). Epecially if any AA is enabled. Some games that do this are Crysis, GRID, UT3, Mass Effect, ET:QW... with older games it does not happen, only newer stuff with higher res textures.
This never happened on my 8800GTX to the same extent. So i put it down to the GX2 not having enough memory bandwidth and enough usable VRAM for such high resolution.
So could you explain how the GX2 is getting 64FPS @ 2560x1600 with 4x AA with ET:Quake Wars? Aswell as other games at that res + AA.
DerekWilson - Monday, June 16, 2008 - link
i really haven't noticed the same issue with menu screens ... except in black and white 2 ... that one sucked and i remember complaining about it.to be fair i haven't tested this with mass effect, grid, or ut3.
as for menu screens, they tend to be less memory intensive than the game itself. i'm really not sure why it happens when it does, but it does suck.
i'll ask around and see if i can get an explaination of this problem and if i can i'll write about why and when it will happen.
thanks,
Derek
larson0699 - Monday, June 16, 2008 - link
"Massiveness" and "aggressiveness"?I know the article is aimed to hit as hard as the product it's introducing us to, but put a little English into your English.
"Mass" and "aggression".
FWIW, the GTX's numbers are unreal. I can appreciate the power-saving capabilities during lesser load, but I agree, GT200 should've been 55nm. (6pin+8pin? There's a motherboard under that SLI setup??)
jobrien2001 - Monday, June 16, 2008 - link
Seems Nvidia finally dropped the ball.-Power consumption and the price tag are really bad.
-Performance isnt as expected.
-Huge Die
Im gonna wait for a die shrink or buy an ATI. The 4870 with ddr5 seems promising from the early benchmarks... and for $350? who in their right mind wouldnt buy one.