The Radeon HD 4850 & 4870: AMD Wins at $199 and $299
by Anand Lal Shimpi & Derek Wilson on June 25, 2008 12:00 AM EST- Posted in
- GPUs
A Quick Primer on ILP
NVIDIA throws ILP (instruction level parallelism) out the window while AMD tackles it head on.
ILP is parallelism that can be extracted from a single instruction stream. For instance, if i have a lot of math that isn't dependent on previous instructions, it is perfectly reasonable to execute all this math in parallel.
For this example on my imaginary architecture, instruction format is:
LineNumber INSTRUCTION dest-reg, source-reg-1, source-reg-2
This is compiled code for adding 8 numbers together. (i.e. A = B + C + D + E + F + G + H + I;)
1 ADD r2,r0,r1
2 ADD r5,r3,r4
3 ADD r8,r6,r7
4 ADD r11,r9,r10
5 ADD r12,r2,r5
6 ADD r13,r8,r11
7 ADD r14,r12,r13
8 [some totally independent instruction]
...
Lines 1,2,3 and 4 could all be executed in parallel if hardware is available to handle it. Line 5 must wait for lines 1 and 2, line 6 must wait for lines 3 and 4, and line 7 can't execute until all other computation is finished. Line 8 can execute at any point hardware is available.
For the above example, in two wide hardware we can get optimal throughput (and we ignore or assume full speed handling of read-after-write hazards, but that's a whole other issue). If we are looking at AMD's 5 wide hardware, we can't achieve optimal throughput unless the following code offers much more opportunity to extract ILP. Here's why:
From the above block, we can immediately execute 5 operations at once: lines 1,2,3,4 and 8. Next, we can only execute two operations together: lines 5 and 6 (three execution units go unused). Finally, we must execute instruction 7 all by itself leaving 4 execution units unused.
The limitations of extracting ILP are on the program itself (the mix of independent and dependent instructions), the hardware resources (how much can you do at once from the same instruction stream), the compiler (how well does the compiler organize basic blocks into something the hardware can best extract ILP from) and the scheduler (the hardware that takes independent instructions and schedules them to run simultaneously).
Extracting ILP is one of the most heavily researched areas of computing and was the primary focuses of CPU design until the advent of multicore hardware. But it is still an incredibly tough problem to solve and the benefits vary based on the program being executed.
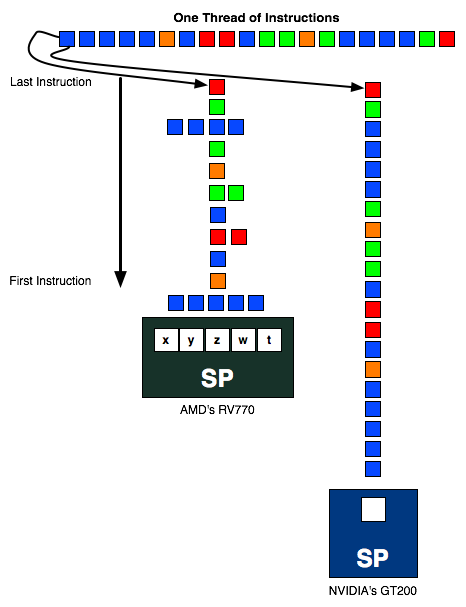
The instruction stream above is sent to an AMD and NVIDIA SP. In the best case scenario, the instruction stream going into AMD's SP should be 1/5th the length of the one going into NVIDIA's SP (as in, AMD should be executing 5 ops per SP vs. 1 per SP for NVIDIA) but as you can see in this exampe, the instruction stream is around half the height of the one in the NVIDIA column. The more ILP AMD can extract from the instruction stream, the better its hardware will do.
AMD's RV770 (And R6xx based hardware) needs to schedule 5 operations per thread every every clock to get the most out of their hardware. This certainly requires a bit of fancy compiler work and internal hardware scheduling, which NVIDIA doesn't need to bother with. We'll explain why in a second.
Instruction Issue Limitations and ILP vs TLP Extraction
Since a great deal of graphics code manipulates vectors like vertex positions (x,y,c,w) or colors (r,g,b,a), lots of things happen in parallel anyway. This is a fine and logical aspect of graphics to exploit, but when it comes down to it the point of extracting parallelism is simply to maximize utilization of hardware (after all, everything in a scene needs to be rendered before it can be drawn) and hide latency. Of course, building a GPU is not all about extracting parallelism, as AMD and NVIDIA both need to worry about things like performance per square millimeter, performance per watt, and suitability to the code that will be running on it.
NVIDIA relies entirely on TLP (thread level parallelism) while AMD exploits both TLP and ILP. Extracting TLP is much much easier than ILP, as the only time you need to worry about any inter-thread conflicts is when sharing data (which happens much less frequently than does dependent code within a single thread). In a graphics architecture, with the necessity of running millions of threads per frame, there are plenty of threads with which to fill the execution units of the hardware, and thus exploiting TLP to fill the width of the hardware is all NVIDIA needs to do to get good utilization.
There are ways in which AMD's architecture offers benefits though. Because AMD doesn't have to context switch wavefronts every chance it gets and is able to extract ILP, it can be less sensitive to the number of active threads running than NVIDIA hardware (however both do require a very large number of threads to be active to hide latency). For NVIDIA we know that to properly hide latency, we must issue 6 warps per SM on G80 (we are not sure of the number for GT200 right now), which would result in a requirement for over 3k threads to be running at a time in order to keep things busy. We don't have similar details from AMD, but if shader programs are sufficiently long and don't stall, AMD can serially execute code from a single program (which NVIDIA cannot do without reducing its throughput by its instruction latency). While AMD hardware can certainly handle a huge number of threads in flight at one time and having multiple threads running will help hide latency, the flexibility to do more efficient work on serial code could be an advantage in some situations.
ILP is completely ignored in NVIDIA's architecture, because only one operation per thread is performed at a time: there is no way to exploit ILP on a scalar single-issue (per context) architecture. Since all operations need to be completed anyway, using TLP to hide instruction and memory latency and to fill available execution units is a much less cumbersome way to go. We are all but guaranteed massive amounts of TLP when executing graphics code (there can be many thousand vertecies and millions of pixels to process per frame, and with many frames per second, that's a ton of threads available for execution). This makes the lack of attention to serial execution and ILP with a stark focus on TLP not a crazy idea, but definitely divergent.
Just from the angle of extracting parallelism, we see NVIDIA's architecture as the more elegant solution. How can we say that? The ratio of realizable to peak theoretical performance. Sure, Radeon HD 4870 has 1.2 TFLOPS of compute potential (800 execution units * 2 flops/unit (for a multiply-add) * 750MHz), but in the vast majority of cases we'll look at, NVIDIA's GeForce GTX 280 with 933.12 GFLOPS ((240 SPs * 2 flops/unit (for multiply-add) + 60 SFUs * 4 flops/unit (when doing 4 scalar muls paired with MADs run on SPs)) * 1296MHz) is the top performer.
But that doesn't mean NVIDIA's architecture is necessarily "better" than AMD's architecture. There are a lot of factors that go into making something better, not the least of which is real world performance and value. But before we get to that, there is another important point to consider. Efficiency.








215 Comments
View All Comments
shadowteam - Wednesday, June 25, 2008 - link
Did you know these chips can do up to 125C? 90C is so common for ATI cards, I haven't had one since 2005 that didn't blow me hair dry. Your NV card was just a bad chip I suppose. Why do you think NV or ATI would spend a billion dollars in research work, then let its product burn away due to some crappy cooling? They won't give you more cooling than you actually need. It's the same very cards that go to places like Abu-Dhabi, where room temps. easily hit 50C+.soloman02 - Wednesday, June 25, 2008 - link
Sorry, but no human would survive a temp of 50C.http://en.wikipedia.org/wiki/Thermoregulation#Hot">http://en.wikipedia.org/wiki/Thermoregulation#Hot
In fact the highest temp a human has survived was recorded by the Guinness book of world records as: 46.5C (115.7F). Keep in mind that was the internal temp of the guy. The temp on that day was 32.2C (90F).
http://www.powells.com/biblio?show=0553587129&...">http://www.powells.com/biblio?show=0553587129&...
http://www.time.com/time/magazine/article/0,9171,9...">http://www.time.com/time/magazine/article/0,9171,9...
If it is 50C in those rooms, the people inside are dead or dying.
The cards are probably fine. All it takes is to search google to back up your figures (or to disprove them like I just did).
shadowteam - Wednesday, June 25, 2008 - link
You're just a dumb pissed off loser. There's a big difference in internal human temperature to its surroundings. In places like Sahara, temperatures routinely hit 45C, and max out @ 55C. But does that mean people living there just die? No they don't, because they drink a lot of water, which helps their bodies get rid of excess heat so to keep their internals at normal temperature (32C). You didn't have this knowledge to share so you decided to Google it instead, and make fool out of yourself. Here, let me break it down for you,You said: "Keep in mind that was the internal temp of the guy"
Exactly, the guy was sick, and when you're sick, your body temperature rises, in which case 46C is the limit of survival. I suggest you take Bio-chemistry in college to learn more about human body, which is another 4 years before you finish school.
Ilmarin - Wednesday, June 25, 2008 - link
I'm not talking about chips failing altogether... just stability issues, similar to what you experience from over-zealous overclocking. Lots of people have encountered artifacting/crashes with stock-cooled cards over the years. If these are just 'bad chips' that are experiencing stability issues at high temps, then there are a lot of them getting through quality control. Of course NV and ATI do enough to make most people happy... but many of us have good reason to be nervous about temperature. I think they can and should do better. Dual slot exhaust coolers should be mandatory for the enthusiast/performance cards, with full fan control capability. Often it's up to the partners to get that right, and often it doesn't happen for at least a couple of months.shadowteam - Wednesday, June 25, 2008 - link
I think it's more profitable for board partners to just roll out a stock card rather than go through the trouble of investing time/money into performance cooling. What I've seen thus far, and it's quite apparent, that newer companies tend to go exotic cooling to get themselves heard. Once they're in the game, it's back to stock cooling. For example, Palit and ECS came up with nice coolers for its 9600s. Remember Leadtek from past years? They don't even do custom coolers any more. ASUS, Powercolor, Gigabyte, Sapphire etc just find it easier to throw in a 3rd party cooler from ZM, TT TR, and call it a day.DerekWilson - Wednesday, June 25, 2008 - link
you know we actually received an updated bios for a certain vendors 4850 that speeds the fan up a bit and should reduce heat ...i suspect a lot of vendors will start adjusting their fan tables actually ...
shadowteam - Wednesday, June 25, 2008 - link
I think this reply was meant for the guy right above me. I'm all for stock cooling :).ImmortalZ - Wednesday, June 25, 2008 - link
"Quake Wars once again shows the 4870 outperforming the GTX 280, but this time it offers essentially the same performance as the GTX 280 - but at half the price. "You mean the 260 in the first instance?
No text in The Witcher page. I assume this is intentional.
Also, I've heard on the web that the 48xx series has dual-link only on one of it's DVI ports. Is this true?
Oh and another thing - why is the post comment page titled "Untitled Page"? :P
rahat5810 - Wednesday, June 25, 2008 - link
Nice cards and nice article. But I would like to point out that there are some mistakes in the article, nothing fatal though. Like, not mentioning 4870 in the list of cards, writing 280 instead of 260, clicking on the picture to enlarge not working for some of the figures.feelingshorter - Wednesday, June 25, 2008 - link
AMD almost has a perfect card but the fact that the 4870 idles at 46.1 more watts than the 260 means the card will heat up people's room. At load, the difference of 16.1 watts more for the 4870 is forgivable.If its possible to overclock a card using software (without going into BIOS screen), then why isn't it possible to underclock a card also using software when the card's full potential isn't being used? I'd really be interested in knowing the answer, or maybe someone just hasn't asked the question?
I hardly care about Crysis, its more a matter of will it run Starcraft II with 600 units on the map without overheating. Why doesn't anandtech also test how hot the 4870 runs? Although the 4850 numbers aren't pretty at all, the 4870 is a dual slot cooler and might give better numbers right? I only want to know because, like a lot of readers, i have doubts as to whether a card like the 4850 can run super hot and not die within 1+ years of hardcore gaming.