The Radeon HD 4850 & 4870: AMD Wins at $199 and $299
by Anand Lal Shimpi & Derek Wilson on June 25, 2008 12:00 AM EST- Posted in
- GPUs
That Darn Compute:Texture Ratio
With its GT200 GPU, NVIDIA increased compute resources by nearly 90% but only increased texture processing by 25%, highlighting a continued trend in making GPUs even more powerful computationally. Here's another glance at the GT200's texture address and filter units:
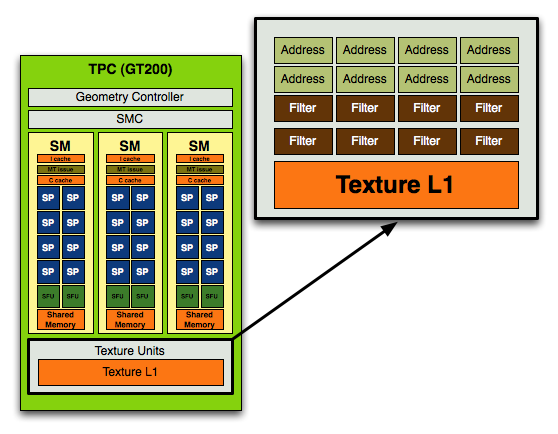
Each TPC, of which there are 10, has eight address and eight filter units. Now let's look at RV770:
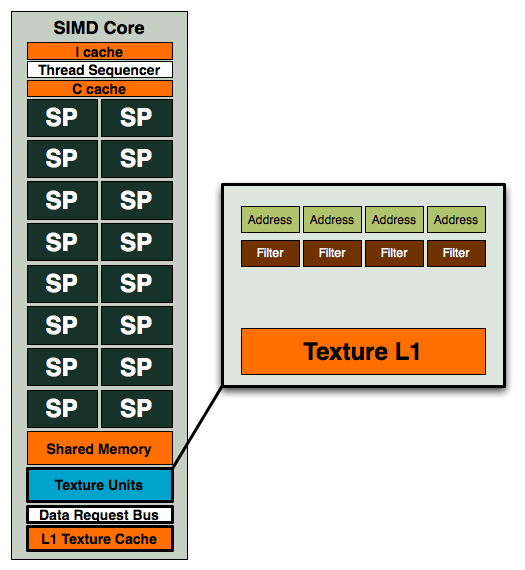
Four address and four filter units, while AMD maintains the same 1:1 address-to-filter ratio that NVIDIA does, the ratio of compute-to-texture in RV770 is significantly higher.
| AMD RV770 | AMD RV670 | NVIDIA GT200 | NVIDIA G92 | |
| # of SPs | 160 | 64 | 240 | 128 |
| Texture Address/Filter Units | 40 / 40 | 16 / 16 | 80 / 80 | 64 / 64 |
| Compute to Texture Ratio | 4:1 | 4:1 | 3:1 | 2:1 |
The table above illustrates NVIDIA's trend of increasing the compute to texture ratio from 2:1 in G92 to 3:1 in GT200. AMD arguably overshot with RV670 and its 4:1 ratio and thus didn't need to adjust it with RV770. Even while staying still at 4:1 with RV770, AMD's ratio is still more aggressively geared towards compute than NVIDIA's is. That does mean that more texture bound games will do better on NVIDIA hardware (at least proportionally), while more compute intensive games may do better on RV770.
AMD did also make some enhancements to their texture units as well. By doing some "stuff" that they won't tell us about, they improved the performance per mm^2 by 70%. Texture cache bandwidth has also been doubled to 480 GB/s while bandwidth between each L1 cache and L2 memory is 384 GB/s. L2 caches are aligned with memory channels of which there are four interleaved channels (resulting in 8 L2 caches).
Now that texture units are linked to both specific SIMD cores and individual L1 texture caches, we have an increase in total texturing ability due to the increase in SIMD cores with RV770. This gives us a 2.5x increase in the number of 8-bit per component textures we can fetch and bilinearly filter per clock, but only a 1.25x increase in the number of fp16 textures (as fp16 runs at half rate and fp32 runs at one quarter rate). It was our understanding that fp16 textures could run at full speed on R600, so the 1.25x increase in performance for half rate texturing of fp16 data makes sense.
Even though fp32 runs at quarter rate, with the types of texture fetches we would need to do, AMD says that we could end up being external memory bandwidth bound before we are texture filtering hardware bound. If this is the case, then the design decision to decrease rates for higher bit-depth textures makes sense.
| AMD RV770 | AMD RV670 | |
| L1 Texture Cache | 10 x 16KB (160KB total) | 32KB |
| L2 Texture Cache | I can has cache size? | 256KB |
| Vertex Cache | ? | 32KB |
| Local Data Share | 16KB | None |
| Global Data Share | 16KB | ? |
Even though AMD wouldn't tell us L1 cache sizes, we had enough info left over from the R600 time frame to combine with some hints and extract the data. We have determined that RV770 has 10 distinct 16k caches. This is as opposed to the single shared 32k L1 cache on R600 and gives us a total of 160k of L1 cache. We know R600's L2 cache was 256k, and AMD told us RV770 has a larger L2 cache, but they wouldn't give us any hints to help out.








215 Comments
View All Comments
paydirt - Wednesday, June 25, 2008 - link
You guys are reading into things WAY too much. Readers understand that just because something is a top performer (right now), doesn't mean that is the appropriate solution for them. Do you honestly think readers are retards and are going to plunk down $1300 for an SLI setup?! Let's leave the uber-rich out of this, get real.So a reader reads the reviews, goes to a shopping site and puts two of these cards in his basket, realizes "woah, hey this is $1300, no way. OK what are my other choices?"
This review doesn't tell people what to do. It's factual. You (the AMD fanbois) are the ones being biased.
Jovec - Wednesday, June 25, 2008 - link
"This fact clearly sets the 4870 in a performance class beyond its price."Or maybe the Nvidia card is priced above its performance class?
DerekWilson - Wednesday, June 25, 2008 - link
it could be both :-)Clauzii - Wednesday, June 25, 2008 - link
I think You are right. nVidia had a little too long by themselves, setting prices as seen fit. Now that AMD/ATI are harvesting the fruits of the merger, overcomming the TLB-bug, financial matters (?), etc. etc. it seems the HD48xx series is right where they needed it.This is bound to be a success for them, with so much (tamable) raw power for the price asked.
Clauzii - Wednesday, June 25, 2008 - link
Yeah! Nice to see competition get into the game again.gigahertz20 - Wednesday, June 25, 2008 - link
Page 21 is labeled "Power Consumption, Heat and Noise" in the drop down page box, but it only lists power consumption figures. What about the heat and noise? Is it loud, quiet? What did the temperatures measure at idle and load?abzillah1 - Wednesday, June 25, 2008 - link
I am in love0g1 - Wednesday, June 25, 2008 - link
"NVIDIA's architecture prefers tons of simple threads (one thread per SP) while AMD's architecture wants instruction heavy threads (since it can work on five instructions from a single thread at once). "Yeah, they both have 10 threads but nV's threads have 24 SP's, AMD's 80 SP's. But the performance will probably be similar because both thread arbiters run about the same speed and nv's SP's run about double the speed, effectively making 48SP's (and in some special cases 96).
ChronoReverse - Wednesday, June 25, 2008 - link
Perhaps it's drivers but if AMD intends for the 4870x2 to compete as the "Fastest Card", they better fix their drivers ASAP.FITCamaro - Wednesday, June 25, 2008 - link
With a few driver revisions it will likely improve.