Intel's Larrabee Architecture Disclosure: A Calculated First Move
by Anand Lal Shimpi & Derek Wilson on August 4, 2008 12:00 AM EST- Posted in
- GPUs
Drilling Deeper and Making the AMD/NVIDIA Comparison
Don't be fooled by the initial diagram, this simple x86 core gets far more complex. In the image below, the block to the left is the Larrabee core we mentioned earlier, to the right we've blown up the vector unit and its associated parts:
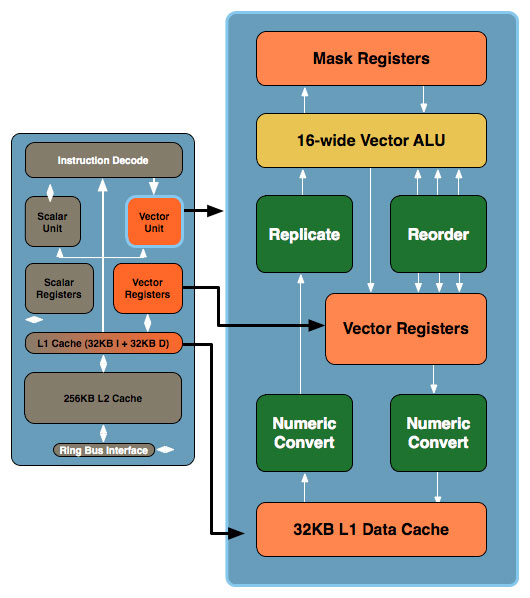
The vector unit is key and within that unit you've got a ton of registers and a very wide vector ALU, which leads us to the fundamental building block of Larrabee. NVIDIA's GT200 is built out of Streaming Processors, AMD's RV770 out of Stream Processing Units and Larrabee's performance comes from these 16-wide vector ALUs:
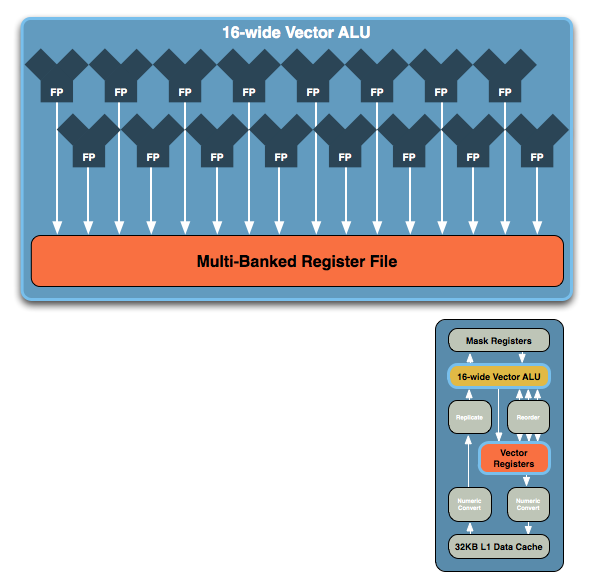
The vector ALU can behave as a 16-wide single precision ALU or an 8-wide double precision, although that doesn't necessarily translate into equivalent throughput (which Intel would not at this point clarify). Compared to ATI and NVIDIA, here's how Larrabee looks at a basic execution unit level:
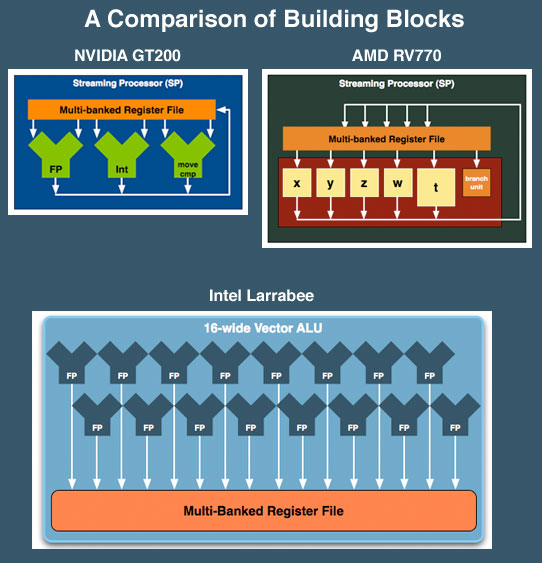
NVIDIA's SPs work on a single operation, AMD's can work on five, and Larrabee's vector unit can work on sixteen. NVIDIA has a couple hundred of these SPs in its high end GPUs, AMD has 160 and Intel is expected to have anywhere from 16 - 32 of these cores in Larrabee. If NVIDIA is on the tons-of-simple-hardware end of the spectrum, Intel is on the exact opposite end of the scale.
We've already shown that AMD's architecture requires a lot of help from the compiler to properly schedule and maximize the utilization of its execution resources within one of its 5-wide SPs, with Larrabee the importance of the compiler is tremendous. Luckily for Larrabee, some of the best (if not the best) compilers are made by Intel. If anyone could get away with this sort of an architecture, it's Intel.
At the same time, while we don't have a full understanding of the details yet, we get the idea that Larrabee's vector unit is sort of a chameleon. From the information we have, these vector units could exectue atomic 16-wide ops for a single thread of a running program and can handle register swizzling across all 16 exectution units. This implies something very AMD like and wide. But it also looks like each of the 16 vector execution units, using the mask registers can branch independently (looking very much more like NVIDIA's solution).
We've already seen how AMD and NVIDIA architectural differences show distinct advantages and disadvantages against eachother in different games. If Intel is able to adapt the way the vector unit is used to suit specific situations, they could have something huge on their hands. Again, we don't have enough detail to tell what's going to happen, but things do look very interesting.








101 Comments
View All Comments
Shinei - Monday, August 4, 2008 - link
Some competition might do nVidia good--if Larrabee manages to outperform nvidia, you know nvidia will go berserk and release another hammer like the NV40 after R3x0 spanked them for a year.Maybe we'll start seeing those price/performance gains we've been spoiled with until ATI/AMD decided to stop being competitive.
Overall, this can only mean good things, even if Larrabee itself ultimately fails.
Griswold - Monday, August 4, 2008 - link
Wake-up call dumbo. AMD just started to mop the floor with nvidias products as far as price/performance goes.watersb - Monday, August 4, 2008 - link
great article!You compare the Larrabee to a Core 2 duo - for SIMD instructions, you multiplied by a (hypothetical) 10 cores to show Larrabee at 160 SIMD instructions per clock (IPC). But you show non-vector IPC as 2.
For a 10-core Larrabee, shouldn't that be x10 as well? For 20 scalar IPC
Adamv1 - Monday, August 4, 2008 - link
I know Intel has been working on Ray Tracing and I'm really curious how this is going to fit into the picture.From what i remember Ray Tracing is a highly parallel and scales quite well with more cores and they were talking about introducing it on 8 core processors, it seems to me this would be a great platform to try it on.
SuperGee - Thursday, August 7, 2008 - link
How it fit's.GPU from ATI and nV are called HArdware renderers. Stil a lot of fixed funtion. Rops TMU blender rasterizer etc. And unified shader are on the evolution to get more general purpouse. But they aren't fully GP.
This larrabee a exotic X86 massive multi core. Will act as just like a Multicore CPU. But optimised for GPU task and deployed as GPU.
So iNTel use a Software renderer and wil first emulate DirectX/OpenGL on it with its drivers.
Like nv ATI is more HAL with as backup HEL
Where Larrabee is pure HEL. But it's parralel power wil boost Software method as it is just like a large bunch of X86 cores.
HEL wil runs fast, as if it was 'HAL' with LArrabee. Because the software computing power for such task are avaible with it.
What this means is that as a GFX engine developer you got full freedom if you going to use larrabee directly.
Like they say first with a DirectX/openGL driver. Later with also a CPU driver where it can be easy target directly. thus like GPGPU task. but larrabee could pop up as extra cores in windows.
This means, because whatever you do is like a software solution.
You can make a software rendere on Ratracing method, but also a Voxel engine could be done to. But this software rendere will be accelerated bij the larrabee massive multicore CPU with could do GPU stuf also very good. But will boost any software renderer. Offcourse it must be full optimised for larrabee to get the most out of it. using those vector units and X86 larrabee extention.
Novalogic could use this to, for there Voxel game engine back in the day's of PIII.
It could accelerate any software renderer wich depend heavily on parralel computing.
icrf - Monday, August 4, 2008 - link
Since I don't play many games anymore, that aspect of Larrabee doesn't interest me any more than making economies of scale so I can buy one cheap. I'm very interested in seeing how well something like POV-Ray or an H.264 encoder can be implemented, and what kind of speed increase it'd see. Sure, these things could be implemented on current GPUs through Cuda/CTM, but that's such an different kind of task, it's not at all quick or easy. If it's significantly simpler, we'd actually see software sooner that supports it.cyberserf - Monday, August 4, 2008 - link
one word: MATROXGuuts - Monday, August 4, 2008 - link
You're going to have to use more than one word, sorry... I have no idea what in this article has anything to do with Matrox.phaxmohdem - Monday, August 4, 2008 - link
What you mean you DON'T have a Parhelia card in your PC? WTF is wrong with you?TonyB - Monday, August 4, 2008 - link
but can it play crysis?!