NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
Architecting Fermi: More Than 2x GT200
NVIDIA keeps referring to Fermi as a brand new architecture, while calling GT200 (and RV870) bigger versions of their predecessors with a few added features. Marginalizing the efforts required to build any multi-billion transistor chip is just silly, to an extent all of these GPUs have been significantly redesigned.
At a high level, Fermi doesn't look much different than a bigger GT200. NVIDIA is committed to its scalar architecture for the foreseeable future. In fact, its one op per clock per core philosophy comes from a basic desire to execute single threaded programs as quickly as possible. Remember, these are compute and graphics chips. NVIDIA sees no benefit in building a 16-wide or 5-wide core as the basis of its architectures, although we may see a bit more flexibility at the core level in the future.
Despite the similarities, large parts of the architecture have evolved. The redesign happened at low as the core level. NVIDIA used to call these SPs (Streaming Processors), now they call them CUDA Cores, I’m going to call them cores.
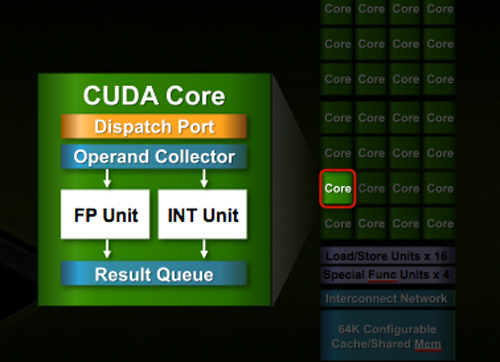
All of the processing done at the core level is now to IEEE spec. That’s IEEE-754 2008 for floating point math (same as RV870/5870) and full 32-bit for integers. In the past 32-bit integer multiplies had to be emulated, the hardware could only do 24-bit integer muls. That silliness is now gone. Fused Multiply Add is also included. The goal was to avoid doing any cheesy tricks to implement math. Everything should be industry standards compliant and give you the results that you’d expect.
Double precision floating point (FP64) performance is improved tremendously. Peak 64-bit FP execution rate is now 1/2 of 32-bit FP, it used to be 1/8 (AMD's is 1/5). Wow.
NVIDIA isn’t disclosing clock speeds yet, so we don’t know exactly what that rate is yet.
In G80 and GT200 NVIDIA grouped eight cores into what it called an SM. With Fermi, you get 32 cores per SM.
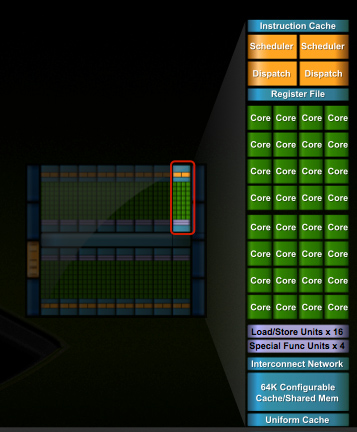
The high end single-GPU Fermi configuration will have 16 SMs. That’s fewer SMs than GT200, but more cores. 512 to be exact. Fermi has more than twice the core count of the GeForce GTX 285.
| Fermi | GT200 | G80 | |
| Cores | 512 | 240 | 128 |
| Memory Interface | 384-bit GDDR5 | 512-bit GDDR3 | 384-bit GDDR3 |
In addition to the cores, each SM has a Special Function Unit (SFU) used for transcendental math and interpolation. In GT200 this SFU had two pipelines, in Fermi it has four. While NVIDIA increased general math horsepower by 4x per SM, SFU resources only doubled.
The infamous missing MUL has been pulled out of the SFU, we shouldn’t have to quote peak single and dual-issue arithmetic rates any longer for NVIDIA GPUs.
NVIDIA organizes these SMs into TPCs, but the exact hierarchy isn’t being disclosed today. With the launch's Tesla focus we also don't know specific on ROPs, texture filtering or anything else related to 3D graphics. Boo.
A Real Cache Hierarchy
Each SM in GT200 had 16KB of shared memory that could be used by all of the cores. This wasn’t a cache, but rather software managed memory. The application would have to knowingly move data in and out of it. The benefit here is predictability, you always know if something is in shared memory because you put it there. The downside is it doesn’t work so well if the application isn’t very predictable.
Branch heavy applications and many of the general purpose compute applications that NVIDIA is going after need a real cache. So with Fermi at 40nm, NVIDIA gave them a real cache.
Attached to each SM is 64KB of configurable memory. It can be partitioned as 16KB/48KB or 48KB/16KB; one partition is shared memory, the other partition is an L1 cache. The 16KB minimum partition means that applications written for GT200 that require 16KB of shared memory will still work just fine on Fermi. If your app prefers shared memory, it gets 3x the space in Fermi. If your application could really benefit from a cache, Fermi now delivers that as well. GT200 did have an L1 texture cache (one per TPC), but the cache was mostly useless when the GPU ran in compute mode.

The entire chip shares a 768KB L2 cache. The result is a reduced penalty for doing an atomic memory op, Fermi is 5 - 20x faster here than GT200.








415 Comments
View All Comments
silverblue - Thursday, October 1, 2009 - link
People will buy nVidia hardware for their HTPCs regardless of it having PhysX, AO, CUDA or whatever. Price is a very attractive factor, but so is noise and temperature, so people will go for what suits them the best. If people think nVidia offers more for the price, they will buy it, some may go for another option if they want less heat, or less speed or whatever. It's their choice, and not one made out of malice.This thread isn't full of nVidia-haters like you want to believe it is. Keep thinking that if you feel more comfortable doing so. In the end, we as consumers have a choice as to what we buy and nothing of what you are saying here has any bearing on that decision making process.
SiliconDoc - Thursday, October 1, 2009 - link
I think I'll just ignore you, since you seem to have acquired a Svengali mind read on your big "we" extension, and somehow think you represent every person here.I don't put any stock in your idiotic lunatic demi-god musings.
--
If you ever say anything worth more than a piece of scat, I will however respond appropriately.
I'll remind you, you can't even prevent YOURSELF from being influenced by me, let alone "everyone here".
Now if you don't have any KNOWLEDGE on the HTPC issues and questions I brought up with this other poster and his HTPC dreams, please excuse your mind reading self, and keep yourself just as deluded as possible.
I find this a classic IDIOCY : " we as consumers have a choice as to what we buy (oh no problem there)
and nothing of what you are saying here has any bearing on that decision making process. "
You just keep telling yourself that, you unbelievably deranged goofball. LOL, and maybe it will become true for you, if you just keep repeating it.
The first sign of your own cracked shield in that area is you actually saying that. You've already been influenced, and you're so goofy, you just had to go in text and claim no one ever will be.
I mean, you are so much worse than anything I've done here it is just amnazing.
How often do you tell yourself fantasies that there is no chance to can possibly believe or prove, and in fact, have likely already failed yourself ?
Really, I mean absolutely.
silverblue - Friday, October 2, 2009 - link
If you had a mind left to form any sort of coherent thought patterns, we might take you seriously here. You have just admitted (in your own incoheret, babbling way) that you are trying to actively (and forcibly, I might add) influence people to buy nVidia cards over ATI. I'm telling you that you've failed and will continue to fail as long as you keep shimmying up and down the green flag pole in the name of progress. I wonder if anyone at nVidia reads these comments; what must they think of you? If they considered AT a biased publication then they wouldn't speak with Anand as cordially as they do.I say "we" because, unless you've opened your eyes, "we" as a community are becoming even more united against no-brained deluded fanboys such as yourself. We DON'T hate nVidia, a lot of people here own nVidia cards, some only have nVidia cards, some own nVidia and ATI, and some own ATI. This isn't about hatred or bias is misinformation; this is about one socially inept weasel who has been attempting to shove his knowledge down everyone else's throats on this (and other subjects) whether there's any factual basis to it or not.
You disagree with me using the term "we", fine. I personally want to see the GT300 launch. I personally want nVidia to bring out a mainstream flavour to compete with the 5850. I personally want prices to fall. I personally don't have anything against PhysX, CUDA or AO. I personally want to see 3D gaming gather momentum.
Now ask yourself - can you be as objective and impartial as that?
You just seem to read what you like and completely miss the point of any post you reply to. There's no way someone can be impartial on this site with you around because any word of praise about ATI equates to bias in your head.
There's only so far you can go before someone clicks the Ban button but I'm sure you'll come back with another account.
shotage - Thursday, October 1, 2009 - link
Still voting to get you banned SiliconDoc.Zool - Thursday, October 1, 2009 - link
I dont think thats to fair from nvidia to let pay the extra cost for design and manufacture from the gpgpu bloat for all people. They lunched tesla card becouse it cost insane money and can get away with curent yields. For majority of graphic is still simd and almosnt no branching uterly enough. I mean if they would make stand alone cuda cards without the useless graphic pipeline parts it could be smaler or faster.And that goes for graphic too.I mean how hard would it be for amd or intel to put some similar low transistor budget simd units to the pipeline to CPU like are in GPU. And they could run on CPU clocks and would be integral part of CPU(latencies, cache etc).
I dont think thats the right strategy for nvidia.
silverblue - Thursday, October 1, 2009 - link
nVidia could charge a premium for the Tesla-badged cards due to their potential savings over the more traditional method of using masses of general-purpose servers, however they may want to really establish Tesla as a viable option so they can't very well charge too much for it.I'm interested in seeing the peak performance figures for both Cypress and Fermi; will the AMD part still have an advantage in raw processing power due to having many many more, if weaker, SPs/cores? And will it matter in the working environment?
Zool - Thursday, October 1, 2009 - link
Nvidias dreams of those 500x performance in the coming years are actualy only for GPGPU not graphic.The curent gen cards are begining to show some strange scaling.(i think nvidia wont be other in this case too)
They will need some more changes if they want to utilize more shader procesors than just double everithing. If u think about it than at 850 MHz feeding 1600 shaders (actualy 320 is more realistic) is quite a transistor chalenge.(CPUs look like babie toys to these with large cache and much less core)
Actualy there are some physical limits to transistors too. Increasing to 4k milion transistors and 3200 shaders in next card would need even more internal speed. It would be maybe easyer to place to rv870 dies in one gpu than double everything.
neomocos - Thursday, October 1, 2009 - link
We all like our freedom of opinions at anand and this article was very interesting and the comments as well that was until SiliconDoc started trashing everything.As stated by a lot of other users i ask anand to take some action against the user , he is ruining my experience and others of calmly reading the articles in the morning with a cofee :).All his arguments and the way he throws them is so random and makes no sense, he sound like a man who needs his drug of praising nvidia and trashing the red rooster any way he can even if it`s with no real arguments.I read with pleasure the comments of the smart non-biased guys posting here but this guy is just talking crap to fill the lines.On topic ... considering what 5850 has : eyefinity , performance/price, directx 11, power cons, and most important availability i was smiling to myself and thinking that ATI will have killer sales this 3 months left of 2009. I personally will wait for nvidia to bring fermi and with it the price war cuz we all know that then all prices will go down i estimate 150$ for 5850 and about 200 for 5870 around june and if nvidia has better price/perf i will definetly buy it.
SiliconDoc - Thursday, October 1, 2009 - link
And, here we have your contribution, after whining about me claiming no points, the usual bs from red lovers, here is the evidence of your bloodshot eyes, at least you've accepted my direct orders and forced yourself to talk topic.-
" On topic ... considering what 5850 has : eyefinity , performance/price, directx 11, power cons, and most important availability i was smiling to myself and thinking that ATI will have killer sales this 3 months left of 2009. "
--
And after you realize what a red rooster you just were, wether you thought it was a good jab at me, since you know I'll read your attack and that's what the attack was about, or wether you couldn't help yourself, you went on to claim how fair and balanced you are after you hoped for 2 cheap ati cards. LOL The afterthought, barely surfacing from the lack of wattage, added at the end, "if nvidia has better I'll blah blah"..
FUNNY how you talk about THOSE CARDS in the TESLA THREAD, when you are ON TOPIC !
roflmao !
Wowzie!
Cocka ! Doodle ! Doooo !
Let me ask you, since you considered eyefinity so great, do you
shotage - Thursday, October 1, 2009 - link
1 vote to get you banned.