NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
Architecting Fermi: More Than 2x GT200
NVIDIA keeps referring to Fermi as a brand new architecture, while calling GT200 (and RV870) bigger versions of their predecessors with a few added features. Marginalizing the efforts required to build any multi-billion transistor chip is just silly, to an extent all of these GPUs have been significantly redesigned.
At a high level, Fermi doesn't look much different than a bigger GT200. NVIDIA is committed to its scalar architecture for the foreseeable future. In fact, its one op per clock per core philosophy comes from a basic desire to execute single threaded programs as quickly as possible. Remember, these are compute and graphics chips. NVIDIA sees no benefit in building a 16-wide or 5-wide core as the basis of its architectures, although we may see a bit more flexibility at the core level in the future.
Despite the similarities, large parts of the architecture have evolved. The redesign happened at low as the core level. NVIDIA used to call these SPs (Streaming Processors), now they call them CUDA Cores, I’m going to call them cores.
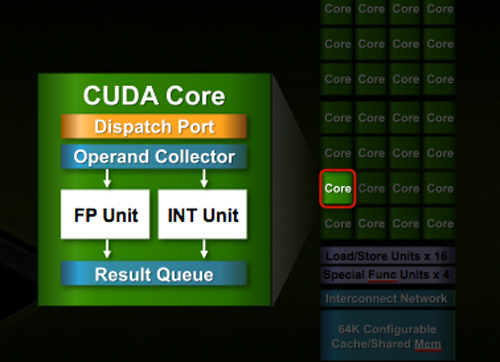
All of the processing done at the core level is now to IEEE spec. That’s IEEE-754 2008 for floating point math (same as RV870/5870) and full 32-bit for integers. In the past 32-bit integer multiplies had to be emulated, the hardware could only do 24-bit integer muls. That silliness is now gone. Fused Multiply Add is also included. The goal was to avoid doing any cheesy tricks to implement math. Everything should be industry standards compliant and give you the results that you’d expect.
Double precision floating point (FP64) performance is improved tremendously. Peak 64-bit FP execution rate is now 1/2 of 32-bit FP, it used to be 1/8 (AMD's is 1/5). Wow.
NVIDIA isn’t disclosing clock speeds yet, so we don’t know exactly what that rate is yet.
In G80 and GT200 NVIDIA grouped eight cores into what it called an SM. With Fermi, you get 32 cores per SM.
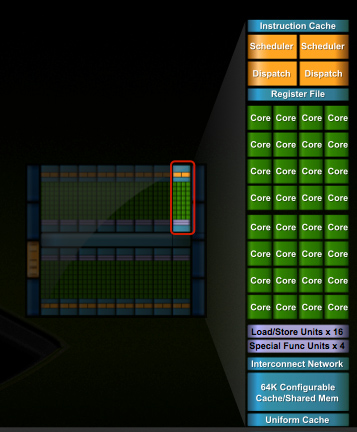
The high end single-GPU Fermi configuration will have 16 SMs. That’s fewer SMs than GT200, but more cores. 512 to be exact. Fermi has more than twice the core count of the GeForce GTX 285.
| Fermi | GT200 | G80 | |
| Cores | 512 | 240 | 128 |
| Memory Interface | 384-bit GDDR5 | 512-bit GDDR3 | 384-bit GDDR3 |
In addition to the cores, each SM has a Special Function Unit (SFU) used for transcendental math and interpolation. In GT200 this SFU had two pipelines, in Fermi it has four. While NVIDIA increased general math horsepower by 4x per SM, SFU resources only doubled.
The infamous missing MUL has been pulled out of the SFU, we shouldn’t have to quote peak single and dual-issue arithmetic rates any longer for NVIDIA GPUs.
NVIDIA organizes these SMs into TPCs, but the exact hierarchy isn’t being disclosed today. With the launch's Tesla focus we also don't know specific on ROPs, texture filtering or anything else related to 3D graphics. Boo.
A Real Cache Hierarchy
Each SM in GT200 had 16KB of shared memory that could be used by all of the cores. This wasn’t a cache, but rather software managed memory. The application would have to knowingly move data in and out of it. The benefit here is predictability, you always know if something is in shared memory because you put it there. The downside is it doesn’t work so well if the application isn’t very predictable.
Branch heavy applications and many of the general purpose compute applications that NVIDIA is going after need a real cache. So with Fermi at 40nm, NVIDIA gave them a real cache.
Attached to each SM is 64KB of configurable memory. It can be partitioned as 16KB/48KB or 48KB/16KB; one partition is shared memory, the other partition is an L1 cache. The 16KB minimum partition means that applications written for GT200 that require 16KB of shared memory will still work just fine on Fermi. If your app prefers shared memory, it gets 3x the space in Fermi. If your application could really benefit from a cache, Fermi now delivers that as well. GT200 did have an L1 texture cache (one per TPC), but the cache was mostly useless when the GPU ran in compute mode.

The entire chip shares a 768KB L2 cache. The result is a reduced penalty for doing an atomic memory op, Fermi is 5 - 20x faster here than GT200.








415 Comments
View All Comments
SiliconDoc - Thursday, October 1, 2009 - link
Yes that is quite disappointing, but the 3 million transistor count and ddr5 somewaht makes up for it, and the fact that we're told by the red roosters that even 153 bandwith is plenty or just a tiny bit shy, and with what it looks like the 384 bit ddr5 4000 or 4800 data GT300 will come in at 192 bandwith minimum, or more likely 240 bandwith, quite a lot higher than 153.6 for ati's 5870.---
So really, what should I believe now, 153 is really plenty except in a few rare instances, or what you say LOL @ Trolls should believe, that 192 or 240 is worse than 153 ?
--
You might LOL @ TRolls, but from my view, you just made an awful fool of yourself.
HINT: The ati 5870 is only 256bit, not 384, and not 512.
Now, look in the mirror and LOL.
sigmatau - Thursday, October 1, 2009 - link
I know the ATI cards have 256 bit connections dumb ass. I'm just using your logic (or lack of it.) ATI has been able to outperform Nvidia cards with their 256 bit connections so your point about bandwidth is meaningless idiot.Now go pull that G295 out your ass, ok?
SiliconDoc - Thursday, October 1, 2009 - link
Golly, that ddr5 has nothing to do with bandwith, right, you stupid idiot ?--
Talk to me about the 4850, you lame, near brain dead, doofus. It's got ddr3 on it.
---
See, that's the other problem for you idiotic true believers, NV is moving from 2248 data rate ram on up to 4800.
But you're so able to keep more than one tiny thought in your stupid gourd at once, you "knew that".
BTW, you're not doing what I'm doing, you're not capable of it.
Now that sourpussed last little whine by you, the 295, beats everything ati has, making your simpleton statement A BIG FAT JOKE.
moltentofu - Thursday, October 1, 2009 - link
My god silicondoc you aren't really succeeding here. At what purpose? To convince people not to buy ati cards? You are such a complete, massive ahole it makes me want to go out and buy ati cards in bulk just to spite you.I'm guessing that if nvidia PR ever watched you rant your all-caps rants they would politely request that you stop associating yourself with their product.
Go ahead everybody google "silicondoc" if you have a strong stomach. Talk about spreading yourself all over the tubes! This guy's fingerprint is unmistakeable. Looks like he got banned on the HondaSwap forums after 14 posts. Guess he sucks on every forum. Maybe anandtech could ban him?
SiliconDoc - Thursday, October 1, 2009 - link
I think every one of you, that instead of actually leaving me alone, or responding with a counter argument to my points, every one of you that merely got logged in, and ripped away at me with an insult ought to be BANNED.That's what really should happen. I make my complaints and arguments on article and cards and companies, and the lies I see about all those, and most, but not all of you, have no response other than a pure trolling, insulting put down.
Every single one of you that came in, and personally attacked me without posting a single comment about the article, YOU are the ones that need to be banned.
Your collective whining is pure personal attack, and instead of commenting on the article, your love or hate for it, you texted up and did one single thing, let loose a rant against me. Just because you could, just because you felt apparently, "it was taking the high road"... which is as ignorant as the lies I've pointed out.
Time for YOU PEOPLE to be banned.
(minus those of course that actually made counterpoints, wether or not they insulted me or complained when they did - because AT LEAST they actually were discussing points, and contributing to the knowledge and opinion groupings.
Like for instance Monkeypaw, who made a reply that wasn't a pure trolling hate filled diatribe like you just posted, having nothing to do with the article at all.
Take a look in the mirror then consider yourself fella.
bobvodka - Thursday, October 1, 2009 - link
In which case I request that YOU are banned for calling ME a liar when I did nothing beyond reply telling you how, on launch day, I ordered a HD5870 and had it the next day.SiliconDoc - Thursday, October 1, 2009 - link
Oh you're full of it again, you pretended your view is the world, and therefore lied your butt off, and in a smart aleck fashion, PERIOD, pretending everyone doesn't know a few trickled out, which if you had clue one, you'd KNOW I was the one who posted that very information on this site.Claiming anyting else, is plain stupid, smart alecky, and LYING.
Just because drunken bob got a card, he claims, on the morning, it shhipped that day, he had it immediately, and has been enojying it ever since, the whole world is satisfied with the paper launch, that "does not exist in bob's drunken vodka world" where who knows what day it is anyeway.
You know, you people are trash,and expecting anyone else to pretend you're not is asking for way too much.
shotage - Thursday, October 1, 2009 - link
SillyDuck - please tone it down. You're getting out of control again!tamalero - Thursday, October 1, 2009 - link
hu.. you'r the one insulting every people who doesnt share your opinion with your "RED ROOSTERS" and other stuff...you're really special Mr. Doc, but in the sad way.
SiliconDoc - Thursday, October 1, 2009 - link
What red roosters, there aren't any here I'm told. Just plain frank and honest people who tell the truth.So if I say red rooster, it cannot possibly mean anyone here, posting, lurking or otherwise, as I'm certain you absolutely know.
( not like coming down to your level takes any effort, there you are special, just for you, so you don't feeel so bad about yourself )