NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
ECC Support
AMD's Radeon HD 5870 can detect errors on the memory bus, but it can't correct them. The register file, L1 cache, L2 cache and DRAM all have full ECC support in Fermi. This is one of those Tesla-specific features.
Many Tesla customers won't even talk to NVIDIA about moving their algorithms to GPUs unless NVIDIA can deliver ECC support. The scale of their installations is so large that ECC is absolutely necessary (or at least perceived to be).
Unified 64-bit Memory Addressing
In previous architectures there was a different load instruction depending on the type of memory: local (per thread), shared (per group of threads) or global (per kernel). This created issues with pointers and generally made a mess that programmers had to clean up.
Fermi unifies the address space so that there's only one instruction and the address of the memory is what determines where it's stored. The lowest bits are for local memory, the next set is for shared and then the remainder of the address space is global.
The unified address space is apparently necessary to enable C++ support for NVIDIA GPUs, which Fermi is designed to do.
The other big change to memory addressability is in the size of the address space. G80 and GT200 had a 32-bit address space, but next year NVIDIA expects to see Tesla boards with over 4GB of GDDR5 on board. Fermi now supports 64-bit addresses but the chip can physically address 40-bits of memory, or 1TB. That should be enough for now.
Both the unified address space and 64-bit addressing are almost exclusively for the compute space at this point. Consumer graphics cards won't need more than 4GB of memory for at least another couple of years. These changes were painful for NVIDIA to implement, and ultimately contributed to Fermi's delay, but necessary in NVIDIA's eyes.
New ISA Changes Enable DX11, OpenCL and C++, Visual Studio Support
Now this is cool. NVIDIA is announcing Nexus (no, not the thing from Star Trek Generations) a visual studio plugin that enables hardware debugging for CUDA code in visual studio. You can treat the GPU like a CPU, step into functions, look at the state of the GPU all in visual studio with Nexus. This is a huge step forward for CUDA developers.
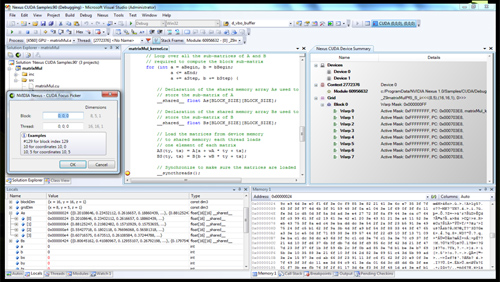
Nexus running in Visual Studio on a CUDA GPU
Simply enabling DX11 support is a big enough change for a GPU - AMD had to go through that with RV870. Fermi implements a wide set of changes to its ISA, primarily designed at enabling C++ support. Virtual functions, new/delete, try/catch are all parts of C++ and enabled on Fermi.








415 Comments
View All Comments
Zingam - Thursday, October 1, 2009 - link
No no! This is just on paper! When will see it for real!! Oh... Q2-3-4 next year! :)So you cannot claim they have the better thing because they don't have it yet! And don't forget next year we might have the head-smashing Larrabee!
:)
Who knows!!! I think you are way to biased and not objective when you type!
chizow - Thursday, October 1, 2009 - link
Heheh if Q2 is what you want to believe when you cry yourself to sleep every night, so be it. ;)Seriously though, its looking like late Q4 or early Q1 and its undoubtedly meant for one single purpose: to destroy the world of ATI GPUs.
As for Larrabee lol...check out some of the IDF news about it. Even Anand hints at Laughabee's failure in his article here. It may compete as a GPGPU extension of x86, but not as a traditional 3D raster, not even close.
SiliconDoc - Thursday, October 1, 2009 - link
Gosh you'd be correct except here is the FERMIhttp://www.fudzilla.com/content/view/15762/1/">http://www.fudzilla.com/content/view/15762/1/
There it is bubba. you blew your yap wide open in ignorance and LOST.
Good job, you've got plenty of company.
ClownPuncher - Thursday, October 1, 2009 - link
Wow, a video card! On top of that pcb could be a cat shit for all we know. The card does not exist, because I can't touch it, I can't buy it, and I can't play games on it.Also, the fact that you seem to get all of your info from Fudzilla speaks volumes. All of your syphillus induced mad ramblings are tiresome.
Lifted - Thursday, October 1, 2009 - link
I see what appears to be a PCB with some plastic attached, and possibly a fan in there as well. Yawn.ksherman - Wednesday, September 30, 2009 - link
Really like these kind of leaps in computing power, I find it fascinating. A shame that it seems nVidia is pulling a bit away from the mainstream graphics segment, but I suppose that means that the new cards from ATI/AMD are the undisputed choice for a graphics card in the next few months. 5850 it is!fri2219 - Wednesday, September 30, 2009 - link
For the love of Strunk and White, stop murdering English in that manner- it detracts from the text buried between banner ads.Sunday Ironfoot - Wednesday, September 30, 2009 - link
nVidia have invented a new way to fry eggs, just crack one open on top of their GPU and play some Crysis. :-)SiliconDoc - Wednesday, September 30, 2009 - link
Let's crack it on page 4. A mjore efficient architecture max threads in flight. Although the DOWNSIDE is sure to be mentioned FIRST as in "not as many as GT200", and the differences mentioned later, the hidden conclusion with the dissing included is apparent.Let's draw it OUT.
---
What should have been said 1st:
Nvidia's new core is 4 times more efficient with threads in flight, so it reduces the number of those from 30,720 to 24,576, maintaining an impressive INCREASE.
---
Yes, now the simple calculation:
GT200 30720x2 = 61,440 GT300 24576x4 = 98,304
at the bottom we find second to last line the TRUTH, before the SLAM on the gt200 ends the page:
" After two clocks, the dispatchers are free to send another pair of half-warps out again. As I mentioned before, in GT200/G80 the entire SM was tied up for a full 8 cycles after an SFU issue."
4 to 1, 4 times better, 1/4th the clock cycles needed
" The flexibility is nice, or rather, the inflexibility of GT200/G80 was horrible for efficiency and Fermi fixes that. "
LOL
With a 4x increase in this core design area, first we're told GT200 "had more" then were told Fermi is faster in terms that allow > the final tale, GT200 sucks.
--
I just LOVE IT, I bet nvidia does as well.
tamalero - Thursday, October 1, 2009 - link
on paper everything looks amazing, just like the R600 did in its time, and the Nvidia FX series as well. so please, just shut up and start spreading your FUD until theres real information, real benches, real useful stuff.