NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
Architecting Fermi: More Than 2x GT200
NVIDIA keeps referring to Fermi as a brand new architecture, while calling GT200 (and RV870) bigger versions of their predecessors with a few added features. Marginalizing the efforts required to build any multi-billion transistor chip is just silly, to an extent all of these GPUs have been significantly redesigned.
At a high level, Fermi doesn't look much different than a bigger GT200. NVIDIA is committed to its scalar architecture for the foreseeable future. In fact, its one op per clock per core philosophy comes from a basic desire to execute single threaded programs as quickly as possible. Remember, these are compute and graphics chips. NVIDIA sees no benefit in building a 16-wide or 5-wide core as the basis of its architectures, although we may see a bit more flexibility at the core level in the future.
Despite the similarities, large parts of the architecture have evolved. The redesign happened at low as the core level. NVIDIA used to call these SPs (Streaming Processors), now they call them CUDA Cores, I’m going to call them cores.
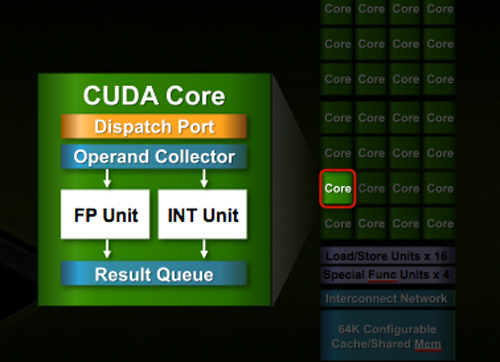
All of the processing done at the core level is now to IEEE spec. That’s IEEE-754 2008 for floating point math (same as RV870/5870) and full 32-bit for integers. In the past 32-bit integer multiplies had to be emulated, the hardware could only do 24-bit integer muls. That silliness is now gone. Fused Multiply Add is also included. The goal was to avoid doing any cheesy tricks to implement math. Everything should be industry standards compliant and give you the results that you’d expect.
Double precision floating point (FP64) performance is improved tremendously. Peak 64-bit FP execution rate is now 1/2 of 32-bit FP, it used to be 1/8 (AMD's is 1/5). Wow.
NVIDIA isn’t disclosing clock speeds yet, so we don’t know exactly what that rate is yet.
In G80 and GT200 NVIDIA grouped eight cores into what it called an SM. With Fermi, you get 32 cores per SM.
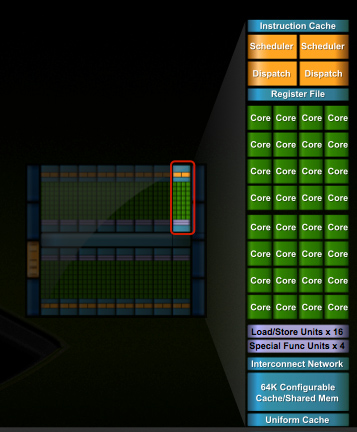
The high end single-GPU Fermi configuration will have 16 SMs. That’s fewer SMs than GT200, but more cores. 512 to be exact. Fermi has more than twice the core count of the GeForce GTX 285.
| Fermi | GT200 | G80 | |
| Cores | 512 | 240 | 128 |
| Memory Interface | 384-bit GDDR5 | 512-bit GDDR3 | 384-bit GDDR3 |
In addition to the cores, each SM has a Special Function Unit (SFU) used for transcendental math and interpolation. In GT200 this SFU had two pipelines, in Fermi it has four. While NVIDIA increased general math horsepower by 4x per SM, SFU resources only doubled.
The infamous missing MUL has been pulled out of the SFU, we shouldn’t have to quote peak single and dual-issue arithmetic rates any longer for NVIDIA GPUs.
NVIDIA organizes these SMs into TPCs, but the exact hierarchy isn’t being disclosed today. With the launch's Tesla focus we also don't know specific on ROPs, texture filtering or anything else related to 3D graphics. Boo.
A Real Cache Hierarchy
Each SM in GT200 had 16KB of shared memory that could be used by all of the cores. This wasn’t a cache, but rather software managed memory. The application would have to knowingly move data in and out of it. The benefit here is predictability, you always know if something is in shared memory because you put it there. The downside is it doesn’t work so well if the application isn’t very predictable.
Branch heavy applications and many of the general purpose compute applications that NVIDIA is going after need a real cache. So with Fermi at 40nm, NVIDIA gave them a real cache.
Attached to each SM is 64KB of configurable memory. It can be partitioned as 16KB/48KB or 48KB/16KB; one partition is shared memory, the other partition is an L1 cache. The 16KB minimum partition means that applications written for GT200 that require 16KB of shared memory will still work just fine on Fermi. If your app prefers shared memory, it gets 3x the space in Fermi. If your application could really benefit from a cache, Fermi now delivers that as well. GT200 did have an L1 texture cache (one per TPC), but the cache was mostly useless when the GPU ran in compute mode.

The entire chip shares a 768KB L2 cache. The result is a reduced penalty for doing an atomic memory op, Fermi is 5 - 20x faster here than GT200.








415 Comments
View All Comments
sandwiches - Thursday, October 1, 2009 - link
Just created an account to say that I've never seen this kind of sycophantic, schizophrenic blathering as Silicondoc. I have been an Nvidia user for the past 7 years or so (simply out of habit) and before that a Voodoo user and I cannot even begin to relate to this buffoon.Oh and to incense him even more, I'd like to add that I bought a HD5870 from newegg a couple nights ago since I needed to upgrade my old 8800 GTS card, NOW... not in a few months or next year. Now. Seeing as how the HD 5870 is the fastest for my buck, I went with that. Forget treating brands like religions. Get whatever's good and you can afford and forget brands. The end.
SiliconDoc - Friday, October 2, 2009 - link
LOL - another lifelong nobody who hasdn't a clue and was a green goblin by habit self reported, made another account, and came in just to "incense" "the debater".Really, you couldn't have done a better job of calling yourself a piece of trash.
Congratulations for that.
You admitted your goal was trolling and fanning the flames.
LOL
That was your goal, and so bright you are, that "sandwiches" came to mind as your name, a complimentary imitation, indicating you hoped to be equal to "Silicon" and decided to take a "tech part" styled name, or, perhaps as likely, it was haphazard chance cause buckey was hungry when he got here, and that's all he could think of.
I think you're another pile of stupid with the C and below crowd, basically.
So, that sort of explains your purchase, doesn't it ?
LOL
Yes, you can't possibly relate, you need more MHZ a lot bigger powr supply "sandwiches".
LOL
sandwiches!
CptTripps - Friday, October 2, 2009 - link
Reading your comments makes me think you are about 12 and in need of serious evaluation. I have never seen someone so out of control on Anand for 30+ pages. Seriously, get your brain checked out, there is some sort of imbalance going on when everyone in the whole world is a liar except you, the only beacon of truth.sandwiches - Friday, October 2, 2009 - link
LMAOThis has to be an online persona for you, Brian. Are you seriously like this in real life?
Voo - Thursday, October 1, 2009 - link
We really need a "ignore this idiot" button :/Anyways, is there any reason why this has to be a "one size fits them all" chip? I mean according to the article there's a lot of stuff in it, which only a minority of gamers would ever need (ECC memory? That's more expensive than normal memory and usually has a performance impact).
I mean there's already a workstation chip, why not a third one for GPU computing?
neomocos - Thursday, October 1, 2009 - link
You know when someone says you are drunk/stupid/drugged/crazy/etc... then you might question him but when 2 or 3 people say it then it`s most than probably true but when all the people at anand say it then SiliconDoc should just stfu, go right now and buy an ati 5870 and smash it on the ground and maby he will feel better and let us be.I vote for ban also :) and i donate 10$ for the 5870 we anand users will give him as a present for christmas.Happy new red year Silicon...
andrihb - Thursday, October 1, 2009 - link
I'm excited about this but I wish it was ready sooner. It looks like we'll have to wait 2-3 months for benchmarks, right?I hope it'll blow 5870 away because that's what is best for us, the consumers. We'll have an even faster GPU available to us which is all that really matters.
I've noticed that a person here has been criticizing this article for belittling the fact that nVidia's upcoming GPU is likely going to have a vastly suerior memory bandwidth to ATI's current flagship. Anand gave us the very limited data that exists at the moment and left most of the speculation to us. He doesn't emphasize that Fermi (which won't even be available for months) has far more bandwidth than ATI's current flagship. I contend that most people already suspected as much.
The vastly superior memmory bandwidth suggests that nVidia might just have a 5870 killer up it's sleeve. See what I just did there? This is called engaging in speculation. Anand could have done more of that, I agree, but saying that this is proof of Anand's supposed bias towards ATI? That is totally unreasonable.
Hey, Doc, do you want to see a real life, batshit crazy, foaming at the mouth fanboy? All you need is a mirror.
JonnyDough - Thursday, October 1, 2009 - link
"Jonah did step in to clarify. He believes that AMD's strategy simply boils down to targeting a different price point. He believes that the correct answer isn't to target a lower price point first, but rather build big chips efficiently. And build them so that you can scale to different sizes/configurations without having to redo a bunch of stuff. Putting on his marketing hat for a bit, Jonah said that NVIDIA is actively making investments in that direction. Perhaps Fermi will be different and it'll scale down to $199 and $299 price points with little effort? It seems doubtful, but we'll find out next year."FOOL!
So nVidia is going to make this for Tesla. That's great that they're innovating but you mentioned that those sales are only a small percentage. AMD went from competing strongly in the CPU market to dominating the GPU market. Good move. But if there's no existing market for the GPGPU...do you really want to be switching gears and trying to create one? Hmm. Crazy!
SiliconDoc - Thursday, October 1, 2009 - link
Admin: You've overstayed your welcome, goodbye.I'm not sure where you got your red rooster lies information. AMD/ati has NO DOMINATION in the GPU market.
---
One moment please to blow away your fantasy...
---
http://jonpeddie.com/press-releases/details/amd-so...">http://jonpeddie.com/press-releases/det...ntel-and...
---
Just in case you're ready to scream I cooked up a pure grteen biased link, check back a few pages and you'll see the liar who claimed ati is now profitable and holding up AMD because of it provided the REAL empty rhetoric fanboy link http://arstechnica.com/hardware/news/2009/07/intel...">http://arstechnica.com/hardware/news/20...-graphic...
which states
" The actual numbers that JPR gives are worth looking at,
which show INTEL dominates the GPU market !
Wow, what a surprise for you. I've just expanded your world, to something called "honest".
So:
INTEL 50.30%
NVIDIA 28.74%
AMD 18.13%
others below 1% each.
------------
Gee, now you know who dominates, and for our discussions here, who is IN LAST PLACE! AND THAT WOULD BE ATI THE LAST PLACE LOSER!
--
Now, I wouldn't mind something like ati is competitive, but that DOMINATES thing says it's #1, and ati is :
************* ATI IS IN LAST PLACE ! LAST PLACE! **************
Now please whine about the 3 listed at the link less than 1% each, so you can "pump up ati" by claiming "it's not last, which of course I would welcome, since it's much better than lying and claiming it's number one.
---
I suspect all you crying ban babies are ready to claim to have found absolutely zero information or contributioon in this post.
tamalero - Thursday, October 1, 2009 - link
huge difference between INTEGRATED GRAPHIC SEGMENT, wich is almost every laptop there and a lot of business computers.versus the DISCRETE MARKET, wich is the GAMING section... where AMD-ATI and NVIDIA are 100%.
get your facts and see a doctor, your delusional attitude is getting annoying.