Better Image Quality: Jittered Sampling & Faster Anti-Aliasing
As we’ve stated before, the DX11 specification generally leaves NVIDIA’s hands tied. Without capsbits they can’t easily expose additional hardware features beyond what DX11 calls for, and even if they could there’s always the risk of building hardware that almost never gets used, such as AMD’s Tessellator on the 2000-4000 series.
So the bulk of the innovation has to come from something other than offering non-DX11 functionality to developers, and that starts with image quality.
We bring up DX11 here because while it strongly defines what features need to be offered, it says very little about how things work in the backend. The Polymorph Engine is of course one example of this, but there is another case where NVIDIA has done something interesting on the backend: jittered sampling.
Jittered sampling is a long-standing technique used in shadow mapping and various post-processing techniques. In this case, jittered sampling is usually used to create soft shadows from a shadow map – take a random sample of neighboring texels, and from that you can compute a softer shadow edge. The biggest problem with jittered sampling is that it’s computationally expensive and hence its use is limited to where there is enough performance to pay for it.
In DX10.1 and beyond, jittered sampling can be achieved via the Gather4 instruction, which as the name implies is the instruction that gathers the neighboring texels for jittered sampling. Since DX does not specify how this is implemented, NVIDIA implemented it in hardware as a single vector instruction. The alternative is to fetch each texel separately, which is how this would be manually implemented under DX10 and DX9.

NVIDIA’s own benchmarks put the performance advantage of this at roughly 2x over the non-vectorized implementation on the same hardware. The benefit for developers will be that those who implement jittered sampling (or any other technique that can use Gather4) will find it to be a much less expensive technique here than it was on NVIDIA’s previous generation hardware. For gamers, this will mean better image quality through the greater use of jittered sampling.
Meanwhile anti-aliasing performance overall received a significant speed boost. As with AMD, NVIDIA has gone ahead and tweaked their ROPs to reduce the performance hit of 8x MSAA, which on previous-generation GPUs could result in a massive performance drop. In this case NVIDIA has improved the compression efficiency in the ROPs to reduce the hit of 8x MSAA, and also cites the fact that having additional ROPs improves performance by allowing the hardware to better digest smaller primitives that can’t compress well.
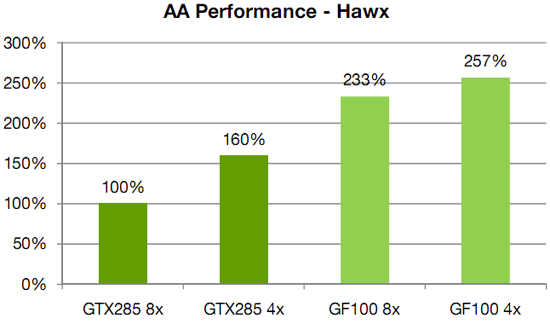
NVIDIA's HAWX data - not independently verified
This is something we’re certainly going to be testing once we have the hardware, although we’re still not sold on the idea that the quality improvement from 8x MSAA is worth any performance hit in most situations. There is one situation however where additional MSAA samples do make a stark difference, which we’ll get to next.








115 Comments
View All Comments
Stas - Tuesday, January 19, 2010 - link
all that hype just sounds awful for nVidia. I hope they don't leave us for good. I like AMD but I like competition more :)SmCaudata - Monday, January 18, 2010 - link
The 50% larger die size will kill them. Even if the reports of lower yields are false they will have to get a much smaller profit margin on their cards than AMD to stay competetive. As it is the 5870 can run nearly any game on a 30" monitor with everything turned up at a playable rate. The target audience for anything more than a 5870 is absurdly small. If Nvidia does not release a mainstream card the only people that are going to buy this beast are the people that have been looking for a reason not to buy and AMD card all along.In the end I think Nvidia will loose even more market share this generation. Across the board AMD is the fastest card at every price point. That will not change and with the dual GPU card already out from ATI it will be a long time before Nvidia has the highest performing card because I doubt they will release a dual GPU card at launch if they are having thermal issues with a single GPU card.
BTW... I've only ever owned Nvidia cards but that will likely change at my next system build even after this "information."
Yojimbo - Monday, January 18, 2010 - link
what do you mean by "information"?SmCaudata - Monday, January 18, 2010 - link
Heh. Just that it was hyped up so much and we really didn't get much other than some architectural changes. I suppose that maybe this is really interesting to some, but I've seen a lot of hardware underperform early spec based guesses.The Anandtech article was great. The information revealed by Nvidia was just okay.
qwertymac93 - Monday, January 18, 2010 - link
I really hope fermi doesn't turn into "nvidias 2900xt". late, hot, and expensive. while i doubt it will be slow by any stretch of the imagination, i hope it isn't TOO hot and heavy to be feasible. i like amd, but nvidia failing is not good for anybody. higher prices(as we've seen) and slower advancements in technology hurt EVERYONE.alvin3486 - Monday, January 18, 2010 - link
Nvidia GF100 pulls 280W and is unmanufacturable , details it wont talk about publiclyswaaye - Monday, January 18, 2010 - link
Remember that they talked all about how wondrous NV30 was going to be too. This is marketing folks. They can have the most amazing eye popping theoretical paper specs in the universe, but if it can't be turned into something affordable and highly competitive, it simply doesn't matter.Put another way, they haven't been delaying it because it's so awesome the world isn't ready for it. Look deeper. :D
blowfish - Monday, January 18, 2010 - link
This was a great read, but it made my head hurt!I wonder how it will scale, since the bulk of the market is for more mainstream cards. (the article mentioned lesser derivatives having less polymorph engines)
Can't wait to see reviews of actual hardware.
Zool - Monday, January 18, 2010 - link
Iam still curious why is nvidia pushing this geometry so hard. With 850 Mhz the cypress should be able to make 850mil polygons/s with one triangel/clock speed. Now thats 14 mil per single frame max at 60fps which is quite unrealistic. Thats more than 7 triangels per single pixel in 1920*1050. Making that amount of geometry in single pixel is quite waste and also botlenecks performance. U just wont see the diference.Thats why amd/ati is pushing also adaptive tesselation which can reduce the tesselation level with copute shader lod to fit a reasonable amount of triangels per pixel.
I can push teselation factor to 14 in the dx9 ATI tesselation sdk demo and reach 100fps or put it on 3 and reach 700+ fps with almost zero difference.
Zool - Tuesday, January 19, 2010 - link
Also want to note that just tesselation is not enough and u always use displacement mapping too. Not to mention u change the whole rendering scene to more shader demanding(shadows,lightning) so to much tesselation (like in uniengine heaven on almost everything, when without tesselation even stairs are flat) can realy make big shader hit.If u compare the graphic quality before tesselation and after in uniengine heaven i would rather ask what the hell is taken away that much performance without tesselation as everything looks so flat like in a 10y old engine.
The increased geometry setup should bring litle to no performance advantage for gf100, the main fps push are the much more eficience shaders with new cache architecture and the more than double the shaders of course.