Intel's Pentium 4 E: Prescott Arrives with Luggage
by Anand Lal Shimpi & Derek Wilson on February 1, 2004 3:06 PM EST- Posted in
- CPUs
Larger, Slower Cache
On the surface Prescott is nothing more than a 90nm Pentium 4 with twice the cache size, but we’ve hopefully been able to illustrate quite the contrary thus far. Despite all of the finesse Intel has exhibited with improving branch predictors, scheduling algorithms and new execution blocks they did exploit one of the easiest known ways to keep a long pipeline full – increase cache size.
With Prescott Intel debuted their highest density cache ever – each SRAM cell (the building blocks of cache) is now 43% smaller than the cells used in Northwood. What this means is that Intel can pack more cache into an even smaller area than if they had just shrunk the die on Prescott.
While Intel has conventionally increased L2 cache size, L1 cache has normally remained unchanged – armed with Intel’s highest density cache ever, Prescott gets a larger L1 cache as well as a larger L2.
The L1 Data cache has been doubled to a 16KB cache that is now 8-way set associative. Intel states that the access latency to the L1 Data cache is approximately the same as Northwood’s 8KB 4-way set associative cache, but the hit rate (probability of finding the data you’re looking for in cache) has gone up tremendously. The increase in hit rate is not only due to the increase in cache size, but also the increase in associativity.
Intel would not reveal (even after much pestering) the L1 cache access latency, so we were forced to use two utilities - Cachemem and ScienceMark to help determine if there was any appreciable increase in access latency to data in the L1.
| Cachemem L1 Latency | ScienceMark L1 Latency | |
|---|---|---|
Northwood |
1 cycle |
2 cycles |
Prescott |
4 cycles |
4 cycles |
Although Cachemem and ScienceMark don't produce identical results, they both agree on one thing: Prescott's L1 cache latency is increased by more than an insignificant amount. We will just have to wait for Intel to reveal the actual access latencies for L1 in order to confirm our findings here.
Although the size of Prescott’s Trace Cache remains unchanged, the Trace Cache in Prescott has been changed for the better thanks to some additional die budget the designers had.
The role of the Trace Cache is similar to that of a L1 Instruction cache: as instructions are sent down the pipeline, they are cached in the Trace Cache while data they are operating on is cached in the L1 Data cache. A Trace Cache is superior to a conventional instruction cache in that it caches data further down in the pipeline, so if there is a mispredicted branch or another issue that causes execution to start over again you don’t have to start back at Stage 1 of the pipeline – rather Stage 7 for example.
The Trace Cache accomplishes this by not caching instructions as they are sent to the CPU, but the decoded micro operations (µops) that result after sending them through the P4’s decoders. The point of decoding instructions into µops is to reduce their complexity, once again an attempt to reduce the amount of work that has to be done at any given time to boost clock speeds (AMD does this too). By caching instructions after they’ve already been decoded, any pipeline restarts will pick up after the instructions have already made it through the decoding stages, which will save countless clock cycles in the long run. Although Prescott has an incredibly long pipeline, every stage you can shave off during execution, whether through Branch Prediction or use of the Trace Cache, helps.
The problem with a Trace Cache is that it is very expensive to implement; achieving a hit rate similar to that of an instruction cache requires significantly more die area. The original Pentium 4 and even today’s Prescott can only cache approximately 12K µops (with a hit rate equivalent to an 8 – 16KB instruction cache). AMD has a significant advantage over Intel in this regard as they have had a massive 64KB instruction cache ever since Athlon. Today’s compilers that are P4 optimized are aware of the very small Trace Cache so they produce code that works around it as best as possible, but it’s still a limitation.
Another limitation of the Trace Cache is that because space is limited, not all µops can be encoded within it. For example, complicated instructions that would take a significant amount of space to encode within the Trace Cache are instead left to be sequenced from slower ROM that is located on the chip. Encoding logic for more complicated instructions can occupy precious die space that is already limited because of the complexity of the Trace Cache itself. With Prescott, Intel has allowed the Trace Cache to encode a few more types of µops inside the Trace Cache – instead of forcing the processor to sequence them from microcode ROM (a much slower process).
If you recall back to the branch predictor section of this review we talked about Prescott’s indirect branch predictor – to go hand in hand with that improvement, µops that involve indirect calls can now be encoded in the Trace Cache. The Pentium 4 also has a software prefetch instruction that developers can use to instruct the processor to pull data into its cache before it appears in the normal execution. This prefetch instruction can now be encoded in the Trace Cache as well. Both of these Trace Cache enhancements are designed to reduce latencies as much as possible, once again, something that is necessary because of the incredible pipeline length of Prescott.
Finally we have Prescott’s L2 cache: a full 1MB cache. Prescott’s L2 cache has caught up with the Athlon 64 FX, which it needs as it has no on-die memory controller and thus needs larger caches to hide memory latencies as much as possible. Unfortunately, the larger cache comes at the sacrifice of access latency – it now takes longer to get to the data in Prescott’s cache than it did on Northwood.
| Cachemem L2 Latency | ScienceMark L2 Latency | |
|---|---|---|
Northwood |
16 cycles |
16 cycles |
Prescott |
23 cycles |
23 cycles |
Both Cachemem and ScienceMark agree on Prescott having a ~23 cycle L2 cache - a 44% increase in access latency over Northwood. The only way for Prescott's slower L2 cache to overcome this increase in latency is by running at higher clock speeds than Northwood.
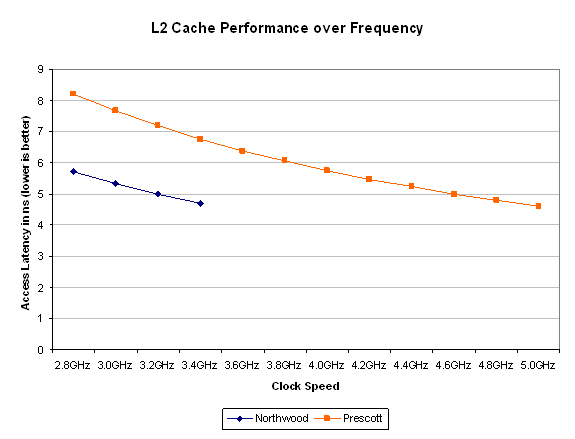
If our cache latency figures are correct, it will take a 4GHz Prescott to have a faster L2 cache than a 2.8GHz Northwood. It will take a 5GHz Prescott to match the latency of a 3.4GHz Northwood. Hopefully by then the added L2 cache size will be more useful as programs get larger, so we'd estimate that the Prescott's cache would begin to show an advantage around 4GHz.
Intel hasn’t changed any of the caching algorithms or the associativity of the L2 cache, so there are no tricks to reduce latency here – Prescott just has to pay the penalty.
For today’s applications, this increase in latency almost single handedly eats away any performance benefits that would be seen by the doubling of Prescott’s cache size. In the long run, as applications and the data they work on gets larger the cache size will begin to overshadow the increase in latency, but for now the L2 latency will do a good job of keeping Northwood faster than Prescott.








104 Comments
View All Comments
INTC - Tuesday, February 3, 2004 - link
CRAMITPAL you must be an ex-Intel disgruntled employee with all of the rage and hatred against the company in you messages. Prescott is a year late? Get serious! Here's the earliest article I could find dated 2/27/02 which says that Prescott was due to launch 2nd half of 2003 http://news.com.com/2100-1001-846382.html. Worst case scenario - even if you count that 2nd half started July 1st then Prescott is 7 months and 1 day delayed - a far cry from a year ago, and a very far cry from the delays of that other chip *cough* *cough* Hammer *cough*! "Special cooling" CRAM? That's probably what your brain needs. I can't seem to find the requirement for special cooling on any of the reviews that have been written thus far - mostly they just used the included HSF in the retail box which even allows for some overclocking too. As far as being slower than Athlon 64 you must need some air cooling on the brain or you must have your selective blinders on again. Page 17 of the Anandtech review http://www.anandtech.com/cpu/showdoc.html?i=1956&a... shows the Prescott 3.2 beating both the Athlon64 3400+ and FX51 in 8 of 9 tests and tying the FX51 in the 9th test - and that's on an Intel 875PBZ that is hobbled in performance compared to a Abit IC7-Max3 or Asus P4C800-E. There's also Aquamark CPU score, DIVX, 3dsmax, lightwave, and in case you didn't read any of the other sites' reviews, you may want to look at MPEG encoding, Photoshop 8, SPECviewperf, oh and real multitasking. I gotta give it to the Athlon64 and FX in games where anything past 30 fps looks just like 30 fps and Microsoft Word and Excel where the program is usually waiting for human input but to say that Prescott "STILL doesn't come close to matching A64 32 bit performance" is ....... well, lets just say that its a good thing that you're not marketing director for all of the companies below:HP plans to offer Prescott chips in HP Pavilion and Compaq Presario desktops that are sold direct to customers, at first. It will start taking orders on them Wednesday.
A Compaq Presario 6000T desktop, for example, will come with a 2.8EGHz Prescott chip, 256MB of RAM, an 80GB hard drive and a CD-ROM for $749 before rebates, Oliver said.
Gateway will also offer Prescott Pentium 4s in its 510 and 710 desktops, without raising its prices. A 510G desktop will feature a 2.8EGHz Prescott and start at $1,099, the company said.
Dell plans to fit some of the new chips into its Dimension desktops and also won't increase prices. Its Dimension XPS game machine will be offered with either the 3.2EGHz Pentium 4, the 3.4GHz Northwood Pentium 4 or the 3.4GHz Pentium 4 Extreme Edition. With the 3.2EGHz chip, the machine will start at $1,799.
Dell will offer the 3.4GHz Northwood Pentium 4 on its Dimension 8300 at first, and will add the 3EGHz and 3.2EGHz Prescott chips by the middle of February, the company said. The 3.4GHz Dimension will start near $1,350.
A number of other PC makers, ranging from IBM to Micro Center, will add desktops with Prescott chips as well.
source: http://news.com.com/2100-1006_3-5151363.html?tag=n...
TrogdorJW - Tuesday, February 3, 2004 - link
In regards to #78, the reason for increasing the pipeline length was to allow for higher clock speeds by doing less work in each pipeline stage. (As the Anandtech article mentions.) A 20 stage Northwood core on 90nm process would probably end up maxed out at around 4.0 GHz, with Intel's typically conservative binning. (You could maybe OC to 4.4 GHz.) With the 31 stage pipeline, it becomes much easier to reach 5.0 GHz.Think about this: at 5 GHz, each clock cycle is .2 ns, or 200 ps. The speed of light can travel a "whopping" 6 cm in that amount of time - in a vacuum! In a copper wire, I think 4 cm might be a better estimate. Now you have to wait for voltages to stabilize and signals to propogate through the transistors. I would think that waiting for the voltages to stabilize probably constitutes the majority of time taken, so now the signals can probably only travel 1 cm.
If that's the case, it becomes pretty clear why they have to have longer and longer pipelines. You can't get signals to stabilize through millions of transistors in 200 picoseconds. Well, maybe you can, but if each stage is cut down to 2 million transistors (~60 million transistors in the Prescott core, with 31 stages total, gives about 2 million per stage) it would definitely take less time for signals to become stable than if you have 3 million transistors per stage (20 stage pipeline with 60 million transistors in the core).
Of course, if the Northwood core is 30 million transistors (29 million, really), a 20 stage pipeline would give 1.5 million transistors per stage. Hmmm... So once again we're back to the 64-bit conspiracy, because where are those extra 30 million transistors being used?
Icewind - Tuesday, February 3, 2004 - link
For some reason, I have a REAL hard time believing a company like Intel would "secretly" put in 64 bit extentions in a new CPU core. Especially one that has pretty much shown it is no better then the current Northwood core.Far as im concered, Intel goes back to drawing board and AMD owns the first part of 2004.
Pumpkinierre - Tuesday, February 3, 2004 - link
Sorry go that wrong should be 43%, so discrepancy even larger ie areawise reduction from .13 to .09 um should be 52% not 43%).Pumpkinierre - Tuesday, February 3, 2004 - link
#77 Trogdor, you beat me to it and with more detail but same estimation- i wont say great minds etc. Increased density of cache may also explain increased latency. However, 13^2 is 169 and 9^2 is 81 which translates to 52% decrease area wise which is close to 47% decrease quoted allowing for other factors like strained silicon.Pumpkinierre - Tuesday, February 3, 2004 - link
Maybe Intel ARE going to bring out a 64bit prescott in a coupla weeks to make up for this let down. Aces reckons there is 30 million transistors unaccounted for, when factoring in the bigger caches (Northwood 55 million transistors, prescott 125 million). Some of this is debugging hardware but that cant be the whole story.With the exception of the caches, the prescott tweaks are good. Why didnt they just do those to the 20 stage pipeline Northwood core? They would have got 30 to 50% more power for the same clock speed and less heat. Geez, I'm happy I bought my northwood in June,03 and I'll probably upgrade to one or a gallatin (if the price drops) unless they sort this heat problem out.
TrogdorJW - Tuesday, February 3, 2004 - link
Interesting article. Frankly, I'm *SHOCKED* that Intel really went with 31 pipeline stages. I had heard the rumors, but I figured someone was using the FP pipeline and not the integer pipeline. Damn... that's a serious penalty to pay for branch mispredictions!What I really want to know, however, is what else the Prescott can do that Intel isn't telling us yet. I've heard all the rumors about 64-bit capability being hidden, but I disgarded them. Now, though, with the specifications released, I honestly have to reconsider. After all, the 30-stage pipeline "rumor" was pretty accurate, so these 64-bit rumors might be as well!
Before you scoff, let me give you some very compelling reasons for Prescott to have hidden 64-bit functionality. Let's start with a quote from the Anandtech article (from page 8): "With Prescott Intel debuted their highest density cache ever – each SRAM cell (the building blocks of cache) is now 43% smaller than the cells used in Northwood. What this means is that Intel can pack more cache into an even smaller area than if they had just shrunk the die on Prescott."
Okay, you got that? As far as I can tell, this means that Intel has improved their SRAM design in the Prescott so that it is smaller - i.e. uses less transistors - than their old SRAM in the Northwood. Sounds reasonable, right? Now, let's reference a different section of the article, on page 11 look at the chart at the bottom. (For a more complete chart, here's a link to THG with both AMD and Intel CPUs: http://www.tomshardware.com/cpu/20040201/images/cp...
Looking at that chart (both Anand and THG have the same numbers, so I'm quite sure they're correct), how many transistors does the P4 Northwood require? The answer is 29 million for the *core*, plus whatever is required for the L2 cache. So the Willamette was 42 mil (13 mil for the 256K L2 cache) and the Northwood is 55 mil (26 mil for the 512K L2 cache). How much space is required for L2 cache, then, based off of Intel's *old* techniques? Apparently, 13 million transistors per 256K of cache. Reasonable enough, since AMD is pretty close to that, judging by the transistor count increase when they went to Barton.
How many transistors would be required, then, for Intel to produce a 1024K L2 cache? In this scenario, 52 million, right? Granted, all caches are not the same: the 2MB L3 cache of the P4EE/Xeon is 30.75 million transistors per 512K, or 15.375 million per 256K, so it's not as "efficient" as the L2 cache design. Still, if we go with 52 million for the 1024K L2 on the Prescott, we end up with 73 million transistors remaining for the CPU core. Even if we go with 61.5 million transistors for the 1024K cache (using the L3 Xeon numbers), we still have 63.5 million transistors left for the core.
So, the original P4 core was 20 stages and 29 million transistors. The Prescott core is 31 stages and somewhere between 60 and 75 million transistors. Even with all of the changes mentioned in the article, I don't see Intel using 30 million transistors just in increasing the pipeline, adding 13 new instructions, and modifying the branch prediction and hyper threading. I suppose I could be wrong, but I am really starting to think that the Prescott might have some unannounced 64-bit capabilities. Rumors often have a kernel of truth in them, you know?
Some other thoughts: Athlon 64 is very much based off of Athlon XP, only with 64-bit extensions and SSE2 support, right? Looking at AMD's chart, the Athlon core took about 22 million transistors, and AMD needed between 16 and 17 million transistors per 256K of L2. If they stuck with those values, a 1024K L2 in the Athlon 64 would require 64 million transistors. The K8 is 105.9 million transistors, so we end up with 42 million remaining transistors in the core. Some of that also had to be used on the newly integrated memory controller. Still, *worst* case, AMD used at most 20 million transistors to add a memory controller, SSE2 support, and 64-bit support to the Athlon XP core. What could Intel possibly be doing with 30 to 40 million transistors, I wonder?
Yes, this is speculation. However, it's speculation based on facts. Maybe Intel doesn't have 64-bit support in Prescott, but I will be really surprised if they don't announce *something* at IDF in a few weeks. 64-bit seems like the likely choice, but maybe there's something else that I missed. Anyone else have any thoughts on this?
Now, some other thoughts. First, how many people have built an Athlon 64 rig? I just built my first this past weekend, and let me tell you, all is NOT sunshine and roses for AMD. I purchased Geil PC3200 Golden Dragon 2-3-3-6 timing RAM - 1 GB in a paired set. Nothing but trouble getting it to work on the AMD!!! Okay, so it was an MSI Neo-FIS2R board; maybe that was the problem? Anyway, I've used the same RAM in P4 systems with no problems.
Running at 2.5-3-3-6 didn't help, although I was able to install Windows XP (it would crash at the 2-3-3-6 timings that were specified in the SPD); once installed, I couldn't complete any benchmarks without crashes. I tried other timings as well; 3-4-4-8 failed to POST and I had to clear the CMOS. Maybe 2.5-4-4-8 would work? I got tired of trying, though. The solution that DID work, unfortunately, was to run the RAM at DDR333 speed and auto (2-3-3-6) timings.
Okay, that said, Athlon 64 3000+ was still plenty fast, and most people won't notice the difference between the top systems except in HPC environments or benchmarks. And the new heatsink, although more difficult to install, is much appreciated. The heat spreader is a welcome addition also. Overall, I was frustrated with the memory problems, but A64 is okay. My advice is to check closely on motherboards and the RAM you'll be using before jumping into the "wonderful" world of Athlon 64. A great page for this (although it will definitely become outdated over time) is at THG:
http://www.tomshardware.com/motherboard/20040112/m...
destaccado - Monday, February 2, 2004 - link
Well, normally I wouldn't agree with Cramitpal just because he is so biased towards AMD but:The message is clear: Intel has failed!
CRAMITPAL - Monday, February 2, 2004 - link
Intel road maps said Prescott would be released a year ago... Intel Press Releases claimed all was fine with 90 nano and "ahead of schedule". Intel is not to be trusted. They released the Enema Edition THREE times with paper launches. The 3.4 Gig. Prescott ain't even available. They are selling CPU rejects IMNHO that will not run at the 3.4 Gig. and faster design speed.Any company that would release what in my opionion and that of others is a defective CPU design, to market for naive, gullible sheep to buy, is fraud. If they couldn't fix this Dog at least don't mislead consumers by releasing an over-heating piece of crap that is SLOWER than the Northwood, uses more electrical power, needs special cooling and STILL doesn't come close to matching A64 32 bit performance, and doesn't do 64 bit at all.
Stlr22 - Monday, February 2, 2004 - link
Would there be a difference in a "sever environment" ?Seems to me like the choice is still obvious. Northwood is the way to go for now.