ATI's Late Response to G70 - Radeon X1800, X1600 and X1300
by Derek Wilson on October 5, 2005 11:05 AM EST- Posted in
- GPUs
Memory Architecture
One of the newest features of the X1000 series is something ATI calls a "ring bus" memory architecture. The general idea behind the design is to improve memory bandwidth effectiveness while reducing cache misses, resulting in overall better memory performance. The architecture already supports GDDR4, but current boards have to settle for the fastest GDDR3 available until memory makers ship GDDR4 parts.
For quite some time, the high end in graphics memory architecture has been a straight forward 256-bit bus divided into four 64-bit channels on the GPU. The biggest issues with scaling up this type of architecture are routing, packaging and clock speed. Routing 256 wires from the GPU to RAM is quite complex. Cards with large buses require printed circuit boards (PCBs) with more layers than a board with a smaller bus in order to compensate for the complexity.
In order to support such a bus, the GPU has to have 256 physical external connections. Adding more and more external connections to a single piece of silicon can also contribute to complexities in increasing clock speed or managing clock speeds between the memory devices and the GPU. In the push for ever improving performance, increasing clock speed and memory bandwidth are constantly evaluated for cost and benefit.
Rather than pushing up the bit width of the bus to improve performance, ATI has taken another approach: improving the management and internal routing of data. Rather than 4 64-bit memory interfaces hooked into a large on die cache, the GPU hass 4 "ring stops" that connect to each other, graphics memory, and multiple caches and clients within the GPU. Each "ring stop" has 2 32-bit connections to 2 memory modules and 2 outgoing 256-bit connections to 2 other ring stops. ATI calls this a 512-bit Ring Bus (because there are 2 256-bit rings going around the ring stops).
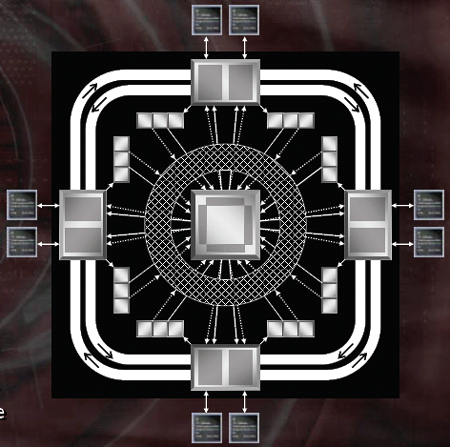
Routing incoming memory through a 512-bit internal bus helps ATI to get data where it needs to go quickly. Each of the ring stops connects to a different set of caches. There are 30+ independent clients that require memory access within an X1000 series GPU. When one of these clients needs data not in a cache, the memory controller forwards the request to the ring stop attached to the physical memory with the data required. That ring stop then forwards the data around the ring to the ring stop (and cache) nearest the requesting client.
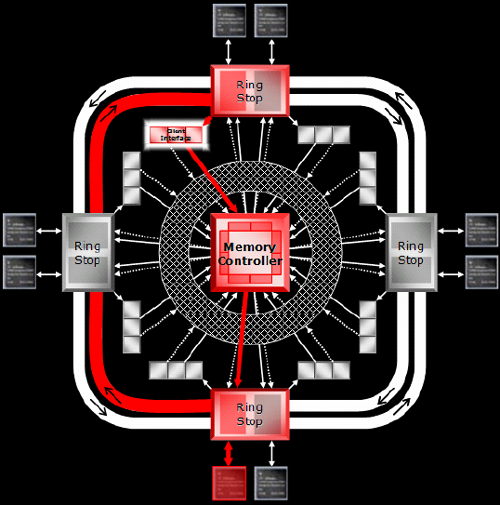
The primary function of memory management shifts to keeping the caches full with relevant information. Rather than having the memory controller on the GPU aggregate requests and control bandwidth, the memory controllers and ring bus work to keep data closer to the hardware that needs it most and can deal with each 32-bit channel independently. This essentially trades bandwidth efficiency for improved latency between memory and internal clients that require data quickly. With writes cached and going though the crossbar switch and the ring bus keeping memory moving to the cache nearest the clients that need data, ATI is able to tweak their caches to fit the new design as well.
On previous hardware, caches were direct mapped or set associative. This means that every address in memory maps to a specific cache line (or set in set associative). With larger caches, direct mapped and set associative designs work well (like L3 and L2 caches on a CPU). If a smaller cache is direct mapped, it is very easy for useful data to get kicked out too early by other data. Conversely, a large fully associative cache is inefficient as the entire cache must be searched for a hit rather than one line (direct mapped) or one block (set associative).
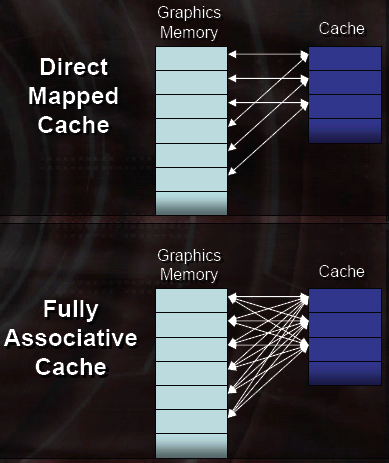
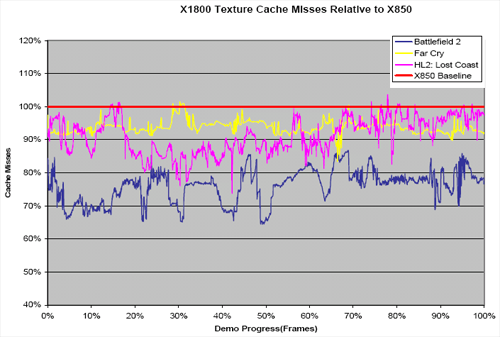
It makes sense that ATI would move to a fully associative cache in this situation. If they had large cache that serviced the entire range of clients and memory, a direct mapped (or more likely some n-way set associative cache) could make sense. With this new ring bus, if ATI split caches into multiple smaller blocks that service specific clients (as it appears they may have done), fully associative caches do make sense. Data from memory will be able to fill up the cache no matter where it's from, and searching smaller caches for hits shouldn't cut into latency too much. In fact, with a couple fully associative caches heavily populated with relevant data, overall latency should be improved. ATI showed us some Z and texture cache miss rates releative to X850. This data indicates anywhere from 5% to 30% improvement in cache miss rates among a few popular games from their new system.
The following cache miss scaling graphs are not data collected by us, but reported by ATI. We do not currently have a way to reproduce data like this. While assuring that the test is impartial and accurate is not possible in this situation (so take it with a grain of salt), the results are interesting enough for us to share them.
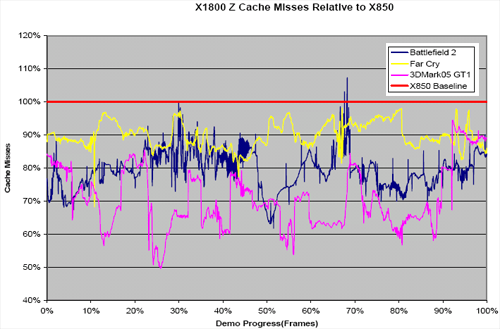
In the end, if common data patterns are known, cache design is fairly simple. It is easy to simulate cache hit/miss data based on application traces. A fully associative cache has its down sides (latency and complexity), so simply implementing them everywhere is not an option. Rather than accepting that fully associative caches are simply "better", it is much safer to say that a fully associative cache fits the design and makes better use of available resources on X1000 series hardware when managing data access patterns common in 3d applications.
Generally, bandwidth is more important than latency with graphics hardware as parallelism lends itself to effective bandwidth utilization and latency hiding. At the same time, as the use of flow control and branching increase, latency could potentially become more important than it is now.
The final new aspect of ATI's memory architecture is programmable bus arbitration. ATI is able to update and adapt the way the driver/hardware prioritizes memory access. The scheme is designed to weight memory requests based on a combination of latency and priority. The priority based scheme allows the system to determine and execute the most critical and important memory requests first while allowing data less sensitive to latency to wait its turn. The impression we have is that requests are required to complete within a certain number of cycles in order to prevent the starvation of any given thread, so the longer a request waits the higher its priority becomes.
ATI's ring bus architecture is quite interesting in and of itself, but there are some added benefits that go along with such a design. Altering the memory interface to connect with each memory device independently (rather than in 4 64-bit wide busses) gives ATI some flexibility. Individually routing lines in 32-bit groups helps to make routing connections more manageable. It's possible to increase stability (or potential clock speed) with simpler connections. We've already mentioned that ATI is ready to support GDDR4 out of the box, but there is also quite a bit of potential for hosting very high clock speed memory with this architecture. This is of limited use to customers who buy the product now, but it does give ATI the potential to come out with new parts as better and faster memory becomes available. The possibility of upgrading the 2 32-bit connections to something else is certainly there, and we hope to see something much faster in the future.
Unfortunately, we really don't have any reference point or testable data to directly determine the quality of this new design. Benchmarks will show how the platform as a whole performs, but whether the improvements come from the pixel pipelines, vertex pipelines, the memory controller, ring architecture, etc. is difficult to say.
One of the newest features of the X1000 series is something ATI calls a "ring bus" memory architecture. The general idea behind the design is to improve memory bandwidth effectiveness while reducing cache misses, resulting in overall better memory performance. The architecture already supports GDDR4, but current boards have to settle for the fastest GDDR3 available until memory makers ship GDDR4 parts.
For quite some time, the high end in graphics memory architecture has been a straight forward 256-bit bus divided into four 64-bit channels on the GPU. The biggest issues with scaling up this type of architecture are routing, packaging and clock speed. Routing 256 wires from the GPU to RAM is quite complex. Cards with large buses require printed circuit boards (PCBs) with more layers than a board with a smaller bus in order to compensate for the complexity.
In order to support such a bus, the GPU has to have 256 physical external connections. Adding more and more external connections to a single piece of silicon can also contribute to complexities in increasing clock speed or managing clock speeds between the memory devices and the GPU. In the push for ever improving performance, increasing clock speed and memory bandwidth are constantly evaluated for cost and benefit.
Rather than pushing up the bit width of the bus to improve performance, ATI has taken another approach: improving the management and internal routing of data. Rather than 4 64-bit memory interfaces hooked into a large on die cache, the GPU hass 4 "ring stops" that connect to each other, graphics memory, and multiple caches and clients within the GPU. Each "ring stop" has 2 32-bit connections to 2 memory modules and 2 outgoing 256-bit connections to 2 other ring stops. ATI calls this a 512-bit Ring Bus (because there are 2 256-bit rings going around the ring stops).
Routing incoming memory through a 512-bit internal bus helps ATI to get data where it needs to go quickly. Each of the ring stops connects to a different set of caches. There are 30+ independent clients that require memory access within an X1000 series GPU. When one of these clients needs data not in a cache, the memory controller forwards the request to the ring stop attached to the physical memory with the data required. That ring stop then forwards the data around the ring to the ring stop (and cache) nearest the requesting client.
The primary function of memory management shifts to keeping the caches full with relevant information. Rather than having the memory controller on the GPU aggregate requests and control bandwidth, the memory controllers and ring bus work to keep data closer to the hardware that needs it most and can deal with each 32-bit channel independently. This essentially trades bandwidth efficiency for improved latency between memory and internal clients that require data quickly. With writes cached and going though the crossbar switch and the ring bus keeping memory moving to the cache nearest the clients that need data, ATI is able to tweak their caches to fit the new design as well.
On previous hardware, caches were direct mapped or set associative. This means that every address in memory maps to a specific cache line (or set in set associative). With larger caches, direct mapped and set associative designs work well (like L3 and L2 caches on a CPU). If a smaller cache is direct mapped, it is very easy for useful data to get kicked out too early by other data. Conversely, a large fully associative cache is inefficient as the entire cache must be searched for a hit rather than one line (direct mapped) or one block (set associative).
It makes sense that ATI would move to a fully associative cache in this situation. If they had large cache that serviced the entire range of clients and memory, a direct mapped (or more likely some n-way set associative cache) could make sense. With this new ring bus, if ATI split caches into multiple smaller blocks that service specific clients (as it appears they may have done), fully associative caches do make sense. Data from memory will be able to fill up the cache no matter where it's from, and searching smaller caches for hits shouldn't cut into latency too much. In fact, with a couple fully associative caches heavily populated with relevant data, overall latency should be improved. ATI showed us some Z and texture cache miss rates releative to X850. This data indicates anywhere from 5% to 30% improvement in cache miss rates among a few popular games from their new system.
The following cache miss scaling graphs are not data collected by us, but reported by ATI. We do not currently have a way to reproduce data like this. While assuring that the test is impartial and accurate is not possible in this situation (so take it with a grain of salt), the results are interesting enough for us to share them.
In the end, if common data patterns are known, cache design is fairly simple. It is easy to simulate cache hit/miss data based on application traces. A fully associative cache has its down sides (latency and complexity), so simply implementing them everywhere is not an option. Rather than accepting that fully associative caches are simply "better", it is much safer to say that a fully associative cache fits the design and makes better use of available resources on X1000 series hardware when managing data access patterns common in 3d applications.
Generally, bandwidth is more important than latency with graphics hardware as parallelism lends itself to effective bandwidth utilization and latency hiding. At the same time, as the use of flow control and branching increase, latency could potentially become more important than it is now.
The final new aspect of ATI's memory architecture is programmable bus arbitration. ATI is able to update and adapt the way the driver/hardware prioritizes memory access. The scheme is designed to weight memory requests based on a combination of latency and priority. The priority based scheme allows the system to determine and execute the most critical and important memory requests first while allowing data less sensitive to latency to wait its turn. The impression we have is that requests are required to complete within a certain number of cycles in order to prevent the starvation of any given thread, so the longer a request waits the higher its priority becomes.
ATI's ring bus architecture is quite interesting in and of itself, but there are some added benefits that go along with such a design. Altering the memory interface to connect with each memory device independently (rather than in 4 64-bit wide busses) gives ATI some flexibility. Individually routing lines in 32-bit groups helps to make routing connections more manageable. It's possible to increase stability (or potential clock speed) with simpler connections. We've already mentioned that ATI is ready to support GDDR4 out of the box, but there is also quite a bit of potential for hosting very high clock speed memory with this architecture. This is of limited use to customers who buy the product now, but it does give ATI the potential to come out with new parts as better and faster memory becomes available. The possibility of upgrading the 2 32-bit connections to something else is certainly there, and we hope to see something much faster in the future.
Unfortunately, we really don't have any reference point or testable data to directly determine the quality of this new design. Benchmarks will show how the platform as a whole performs, but whether the improvements come from the pixel pipelines, vertex pipelines, the memory controller, ring architecture, etc. is difficult to say.








103 Comments
View All Comments
HamburgerBoy - Wednesday, October 5, 2005 - link
Seems kind of odd that you'd include nVidia's best but not ATi's.cryptonomicon - Wednesday, October 5, 2005 - link
I was expecting ATI to make a comback here, but the performance is absolutely abysmal in most games. I dont know what else to say except this product is just gonna be sitting in shelves unless the price is cut severely.bob661 - Thursday, October 6, 2005 - link
LOL! I wouldn't say abysmal. Abysmal would be the X1800XT performing like a 6600GT. The card that doesn't do well is the X1600. X1800's are fantastic performers and certainly much better than my 6600GT at displaying all of a games glory. It just wasn't the ass kicker most everyone hyped it up to be. But technically speaking, it IS an ass kicker.flexy - Wednesday, October 5, 2005 - link
i am a bit disappointed - while at work i overflew the other reviews and then, as the crowning end of my day i read the AT review.I (and probably many others) were waiting for this card like it's the best think since sliced bread - and now, WAY too late we do *indeed* have a good card - but a card which is a contender to NV's offerings and nothing groundbreaking.
Don't get me wrong - better AF/AA is something i always have a big eye on, but then ATI always had this slight edge when it came to AF/AA.
The pure performance in FPS itself is rather sobering - just what we're used to the last few years...usually we have TWO high-end cards out which are PRETT MUCH comparable - and no card is really the "sliced bread" thing which shadows all others.
This is kind of sad.
The price also plays a HUGE factor - and amongst the nice AA/AF features i have a hard time to legitimate say spending $500 for "this edge"...especially as someone who already owns a X850XT .
Not as long i am still playable in HL2/DOD/Lost Coats etc....i dont think i will see FPS fall *that quick* - in other words: I can "afford" to wait longer (R580 ?) and wait for appropriate Game engines (UT2K4 ??) which would make it necessary for me to ditch my X850XT because the X850 got "slow".
D3/OpenGL performance is still disappointing - but then i dont know what NV-specific code D3 uses - but still sad to see this card getting it in the face even if it now has SM3.0 and everything.
Availability:
Well..here we go again....
Bottomline: If i were rich and the card would be orderable RIGHT NOW i would get the XT - no question.
But since i am not rich and the card is *a bit* a disappointment and obviously NOT EVEN AVAILABLE - i will NOT get this card.
It's time to sit back, relax, enjoy my current hardware, watch the prices fall, watch the drivers get better...and then, maybe, one day get one of those or A R580 :)
I WISHED it would NOT have been a day making one "sit and relax" but instead burst out in joy and enthusiasm....but well, then this is real life :)
Wesleyrpg - Thursday, October 6, 2005 - link
summarised very well mate!Regs - Wednesday, October 5, 2005 - link
They were likely better off trying to market that we didn't need new video cards this year and save their capital for next year. These performance charts, especially the "mid range" parts are awfully embarrassing to their company.photoguy99 - Wednesday, October 5, 2005 - link
I assume it was not one of the cards that come overclocked stock to 490Mhz?It seems like it would be fair to use a 490Mhz NVidia part since manufacturers are selling them at that speed out of the box with full warrenty intact.
Evan Lieb - Wednesday, October 5, 2005 - link
"Unless you want image quality."There is no image quality difference, and I doubt you've used either card. Fact of the matter is that you'll never notice IQ differences in the vast majority of the games today. Hell, it's even hard to notice differences in slower paced games like Splinter Cell. The reality is that speed is and always will be the number one priority, because eye candy doesn't matter if you're bogged down by choppy frame rate.
Right now, there is zero reason to want to purchase these cards, if you can even find them. That's fact. Accept it and move on until something else is released.
Madellga - Thursday, October 6, 2005 - link
Quality includes also playing a game without shimmering. I can't get that on my 7800GTX.Before anyone replies, the 78.03 drivers improve a lot the problem but does not fix it.
The explanation is inside Derek's article:
"Starting with Area Anisotropic (or high quality AF as it is called in the driver), ATI has finally brought viewing angle independent anisotropic filtering to their hardware. NVIDIA introduced this feature back in the GeForce FX days, but everyone was so caught up in the FX series' abysmal performance that not many paid attention to the fact that the FX series had better quality anisotropic filtering than anything from ATI. Yes, the performance impact was larger, but NVIDIA hardware was differentiating the Euclidean distance calculation sqrt(x^2 + y^2 + z^2) in its anisotropic filtering algorithm. Current methods (NVIDIA stopped doing the quality way) simply differentiate an approximated distance in the form of (ax + by + cz). Math buffs will realize that the differential for this approximated distance simply involves constants while the partials for Euclidean distance are less trivial. Calculating a square root is a complex task, even in hardware, which explains the lower performance of the "quality AF" equation.
Angle dependant anisotropic methods produce fine results in games with flat floors and walls, as these textures are aligned on axes that are correctly filtered. Games that allow a broader freedom of motion (such as flying/space games or top down view games like the sims) don't benefit any more from anisotropic filtering than trilinear filtering. Rotating a surface with angle dependant anisotropic filtering applied can cause noticeable and distracting flicker or texture aliasing. Thus, angle independent techniques (such as ATI's area aniso) are welcome additions to the playing field. As NVIDIA previously employed a high quality anisotropic algorithm, we hope that the introduction of this anisotropic algorithm from ATI will prompt NVIDIA to include such a feature in future hardware as well. "
Phantronius - Wednesday, October 5, 2005 - link
Unless you a fanboy