SUN’s UltraSparc T1 - the Next Generation Server CPUs
by Johan De Gelas on December 29, 2005 10:03 AM EST- Posted in
- CPUs
Introduction
SUN's Ultrasparc T1, formerly known as Niagara, is much more than just a new UltraSparc. It is the harbinger of a new generation of CPUs, which focus almost solely on Thread Level Parallelism. No less than 32 independent parts of a different program (threads) can be "in flight" on the chip. It is SUN's first implementation of their Throughput computing philosophy, and compared to what we are used to in the AMD/Intel world, it is a pretty extreme architecture that focuses on network and server performance.
Stubborn Server applications
The basic idea behind the UltraSparc T1 is that most modern superscalar Out-Of-Order CPUs may be excellent for games, digital content creation and scientific calculations, but they are not a good match for commercial server loads.
These complex CPUs can decode up to 3 (Opteron) to 8 (Power 5) instructions in parallel, put in a buffer and try to issue them across 9 or more units. In theory, these CPUs can decode, issue, execute and retire up to 3 (Opteron) to 5 (IBM Power) instructions per clock cycle. They have huge buffers (up to 200 instructions) to keep many instructions in flight.
Server workloads, however, cannot make good use of all this parallelism for several reasons. The main reason is that commercial server loads move a lot of data around and perform relatively little calculation on that data. Moving a lot of data around means that you may need a lot of accesses to the memory, which results in many cycles wasted while the CPU has to wait for the data to arrive. As many different users query different parts of the database, caching cannot be as efficient (low locality of reference). In the past years, memory latency has become worse as memory speed increased a lot slower than the speed of the CPU. Memory latency is even worse on MP (Multi-Processor) systems, and has risen from a few tens of CPU cycles to 200-400 clock cycles. The second reason is that many of the calculations performed on that data involve data dependent (read: hard to predict) branches, which makes it even harder to do a lot in parallel.
You might counter these two problems by eliminating the branches through predication and incorporate very large caches. That is what the Itanium family does, but even the mighty Itanium is not capable of running those server loads at high speeds despite predication and gigantic caches. Below, you can see Intel's own numbers for CPU utilization on the 3 different workloads.
The applications that can be found inside Spec Integer benchmark are still rather compute-intensive compared to server applications. Compression, FPGA Circuit Placement and Routing, Compiling and interpreting, and computer visualization are representatives of very CPU intensive integer loads. On average, the best desktop CPUs such as the Athlon 64 or Intel Dothan are capable of sustaining 0.8 to 1 instructions per clock cycle in this benchmark, while the Pentium 4 is around 0.5-0.7 IPC. Itanium is capable of a 1.3-1.5 IPC. That may sound like very low numbers, but let us compare SpecInt with typical server loads. In the table below, you find how the 4-way superscalar USIIIi does on the various benchmarks.
Rather than focus on the absolute numbers, it is more important to note that web applications have 3 times less IPC than CPU intensive integer apps. OLTP databases (TPC-C) do even worse: the CPU sustains on average 0.2 instructions per clock pulse, or 4.5 less than SpecInt. These numbers are no different for the Opteron or Xeon. So despite Out of Order execution, nifty branch prediction schemes and big caches, commercial server loads utilize a very meagre 10 to 15% of the potential of modern CPUs.
One possible solution is to focus on clock speed instead of trying to process as many instructions in parallel (ILP, instruction level parallelism). The long pipelines of such CPUs make the branch prediction problem worse, and the power consumption goes up exponentially as we discussed in a previous article about dynamic power and power leakage.
SUN's Ultrasparc T1, formerly known as Niagara, is much more than just a new UltraSparc. It is the harbinger of a new generation of CPUs, which focus almost solely on Thread Level Parallelism. No less than 32 independent parts of a different program (threads) can be "in flight" on the chip. It is SUN's first implementation of their Throughput computing philosophy, and compared to what we are used to in the AMD/Intel world, it is a pretty extreme architecture that focuses on network and server performance.

Fig 1. The 2U SUN T2000
Stubborn Server applications
The basic idea behind the UltraSparc T1 is that most modern superscalar Out-Of-Order CPUs may be excellent for games, digital content creation and scientific calculations, but they are not a good match for commercial server loads.
These complex CPUs can decode up to 3 (Opteron) to 8 (Power 5) instructions in parallel, put in a buffer and try to issue them across 9 or more units. In theory, these CPUs can decode, issue, execute and retire up to 3 (Opteron) to 5 (IBM Power) instructions per clock cycle. They have huge buffers (up to 200 instructions) to keep many instructions in flight.
Server workloads, however, cannot make good use of all this parallelism for several reasons. The main reason is that commercial server loads move a lot of data around and perform relatively little calculation on that data. Moving a lot of data around means that you may need a lot of accesses to the memory, which results in many cycles wasted while the CPU has to wait for the data to arrive. As many different users query different parts of the database, caching cannot be as efficient (low locality of reference). In the past years, memory latency has become worse as memory speed increased a lot slower than the speed of the CPU. Memory latency is even worse on MP (Multi-Processor) systems, and has risen from a few tens of CPU cycles to 200-400 clock cycles. The second reason is that many of the calculations performed on that data involve data dependent (read: hard to predict) branches, which makes it even harder to do a lot in parallel.
You might counter these two problems by eliminating the branches through predication and incorporate very large caches. That is what the Itanium family does, but even the mighty Itanium is not capable of running those server loads at high speeds despite predication and gigantic caches. Below, you can see Intel's own numbers for CPU utilization on the 3 different workloads.
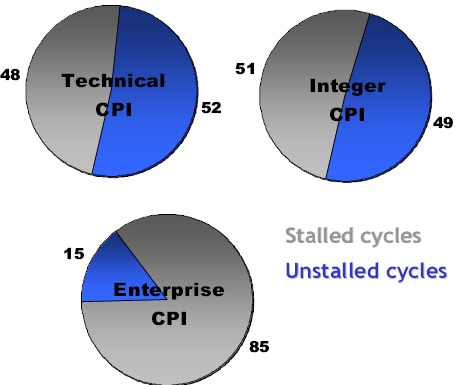
Fig 2: Intel reporting the percentage of stalled cycles of different applications on the Itanium 2 family. Source:Intel.
The applications that can be found inside Spec Integer benchmark are still rather compute-intensive compared to server applications. Compression, FPGA Circuit Placement and Routing, Compiling and interpreting, and computer visualization are representatives of very CPU intensive integer loads. On average, the best desktop CPUs such as the Athlon 64 or Intel Dothan are capable of sustaining 0.8 to 1 instructions per clock cycle in this benchmark, while the Pentium 4 is around 0.5-0.7 IPC. Itanium is capable of a 1.3-1.5 IPC. That may sound like very low numbers, but let us compare SpecInt with typical server loads. In the table below, you find how the 4-way superscalar USIIIi does on the various benchmarks.
| Benchmark | IPC |
| SPECint | 0.9 |
| SPECjbb | 0.5 |
| SPECweb | 0.3 |
| TPC-C | 0.2 |
Rather than focus on the absolute numbers, it is more important to note that web applications have 3 times less IPC than CPU intensive integer apps. OLTP databases (TPC-C) do even worse: the CPU sustains on average 0.2 instructions per clock pulse, or 4.5 less than SpecInt. These numbers are no different for the Opteron or Xeon. So despite Out of Order execution, nifty branch prediction schemes and big caches, commercial server loads utilize a very meagre 10 to 15% of the potential of modern CPUs.
One possible solution is to focus on clock speed instead of trying to process as many instructions in parallel (ILP, instruction level parallelism). The long pipelines of such CPUs make the branch prediction problem worse, and the power consumption goes up exponentially as we discussed in a previous article about dynamic power and power leakage.








49 Comments
View All Comments
sgtroyer - Wednesday, January 4, 2006 - link
Another fascinating article, Johan. It's fun to see Anandtech spending more time delving into architecture and non x86 processors, and doing more analysis and less benchmarking. Keep it up!Scarceas - Friday, December 30, 2005 - link
Remember the converse: Most cpus give up thread level performance...Remember the intended market...
Remember not all 32 threads have to come from one app...
Betwon - Friday, December 30, 2005 - link
Remember: Not come from one app... is not equal to parallel-well:It is possible that it is more slow(many apps work together at the same time) than work one by one.
a core have only 8KB L1, but have to be split for 4 threads to use.It is too few L1 for 4-thread!
Xeon have 16KB for 2 threads, POWER5 have 32KB for 2 threads.
"Most cpus give up thread level performance..." ?
Remember: The Xeon from Intel and POWER5 from IBM --both are multi-thread CPU.
Cerb - Friday, December 30, 2005 - link
Sun stands to gain quite a bit from this, but not really at the expense of IBM, AMD, or Intel. This is doing something that the other guys aren't trying to do, rather than competing against them at what they do well. It is not the future of desktop CPUs. It will not be even a good general-purpose server CPU. It takes a lot of data in, and pushes a lot of data out. A workload that hinges on doing that, without much actual work done to that data, is all it is made to do.It is basically a network appliance that happens to run generic programs on it. If you need that it offers, it will be Lord and Master of your rack. If you're not sure, you will pass it by; because you know that that Opteron over here can take anything you throw at it pretty well.
Betwon - Friday, December 30, 2005 - link
If all people think the your words is correct, SUN may cry.So small areas for it's apps.
Cerb - Friday, December 30, 2005 - link
Why would they cry? They even go to pointing out it's crap for FPU tasks (well, if you notice it lacking entirely in the whole of the PR stuff for it), and tasks with high ILP and IPC (where our mainstream CPUs excel). They also still have a full line-up of other servers, including those based on their own updated SPARCs. It appears their buzzword for this stuff here is 'throughput computing'. Their own brochure for this thing also clearly sell it for high TLP and large data workloads. For more general work, they've got Opterons, and the UltraSPARC IV+ does not appear to be a slouch.Let's look at their own "key applications":
* Web and application tier workloads
Lots of web server threads. Lots of DB threads. Simple integer logic.
* Multithreaded workloads
See above.
* Java application servers and Java Virtual Machines
They're sun. Regardless of how good it may or may not be here, they must market Java™. McNealy has to eat, you know :).
* Consolidated web servers
Basically the first one/two, but worded differently, to point out that it can do 2x as much web serving work as other servers in the rack with it, and maybe even more, while using little power.
* Infrastructure services (portal, directory, identity)
Data in, shuffle it, pump it out. Only slightly different than the rest so far (except Java).
* Enterprise applications (ERP, CRM, SCM business logic)
Again, mostly simple DB work where a lot of things may be going on at once, but plenty of them will really be separate from each other. What each task lags in will be made up for by being able to run another 30 at the same time.
Note that nothing like engineering, scientific simulations, etc., is on that list (things that do a lot of FPU work in parallel). It's basically web and DB said in different ways, and a plug for Java. In addition, their benchmarks look carefully chosen, but not cooked, like Apple's.
Betwon - Friday, December 30, 2005 - link
Just for web server/links, very local java apps?You think that the key of DB works and web server is the multi-thread-parallel performance.It seems that the multi-threads processor(such as P4 Xeon with HT and POWER5 with SMT) is more competitive than the single-thread processor(such as opteron).
Cerb - Friday, December 30, 2005 - link
Just for web server/links, very local java apps?No, not local java apps. Java is only there as marketing, because this is something Sun in trying to sell. Java probably works fine on it, but really has nothing to do with any of it, except that the same company is behind it and this chip.
You think that the key of DB works and web server is the multi-thread-parallel performance.It seems that the multi-threads processor(such as P4 Xeon with HT and POWER5 with SMT) is more competitive than the single-thread processor(such as opteron).
All of those are multithreaded processors. A 386 is a multithreaded processor (in fact, its ability to handle threading in hardware is part of how Linux got created!). However, except for the Power5, none of those can run more than a single thread at a time per core. They can run tons and tons of instructions at a time, but not separate threads (yes, even with HT).
I don't know how IBM's SMT works, but Intel's is nothing like what the T1 is doing. The T1 seems to be made to send out threads without regard to whether one needs replacing or not.
Let's say your task has an IPC of 3, and you have 4 paths to use at a time.
***0
Not bad, 75% used. Now, let's say it's only 1.
*000
25%, not so great. But, because you have to send them in sets of 4, you can't get 3 more in.
OK, now, enter Hyperthreading. Let's go to 2 of those 3-IPC tasks.
***0 ***0
Hey, wait, it didn't use that extra one. 75% again. With HT, it switches the whole thing between threads fast. This help make up for the stalling that will happen a fair bit on the Netburst chips. You can't actually get more done--you just don't have to wait as long when something can't go on, because another one is ready to take its place. yes, it may help a little, but there is also the possibility the CPU will get too loaded down and decrease performance, too.
So, apply that to two 1 IPC tasks.
*000 *000
You're still only using 25%, there. You may get a little boost here or there, when one stalls and the other does not, but you've still got about 3/4 of it wasted.
Now, let's take one core of that T1. It runs four threads, each single-width. So, to that 3 IPC task:
*000, *000, *000
One path of the four is used, going over it three times, because it can't span them out and run them in parallel. So, it will take 3 passes to do the work the others can do in 1. Even with a very short pipeline, that hurts. For this task, the 'fat' CPUs, like the Opteron, are excellent.
But, let's go and run 3 1 IPC tasks, instead:
***0
Now, it got 75% used. Now, running 3x 1 IPC tasks on the Xeon or Opteron:
*000, *000, *000
Not so great. The OoOE, branch prediction, and large local caches help, but it just can't keep up, because it's only one thread at a time.
While this is a very specific kind if workload, the majority of machines that you use on the internet, and many that you may use within a large company, are basically that kind of workload.
Get request for data.
Fetch data.
Check where data needs to go.
Send it there.
The thing about it is that this workload accounts for the majority of what goes on over the internet, and most other networks. As long as your servers have enough work to do during peak times to keep one of these machines somewhat busy, it could save rack space, power use, and increase performance in the process.
Hopefully I didn't screw too much of that up--I did ramble a bit.
Schmide - Saturday, December 31, 2005 - link
As always correct me where I’m wrong.Ok this all works fine if you’re dealing with a non-superscaler 386. But the processors you’re referring to are fully pipelined out of order micro-opp architectures.
I believe the Opteron can have 72 instructions in flight at any one given time, the Power something like 200(x2?), and the P4 126. Each in various levels of decode, process and write.
As for the thread level parallelism, it is in no way as granular as you portray it. Think more in milliseconds not ticks. I believe thread quantums (time slice) for windows are on the order of 30ms. So a 2gh processor task switch occurs, if the thread holds its slice for more than its allotted time, in 6mhz of ticks.
HyperThreading does by definition feeds the execution units from two threads at a time; however, this doesn’t ever reach the level of instruction level parallelism that you portray it just kind of fills in the gaps.
Each core of the Niagara can by theory achieve an ILP of 0.7. Multiply that by 8 and you get a theoretical 5.7 IPC. (but even the ItainumII never reaches the theoretical). Something always gets in the way.
I think the Niagara has some promise.
Betwon - Thursday, December 29, 2005 - link
How terrible for the single thread apps!NO branch prediction!
Someone must be crazy!