AMD's Hammer Architecture - Making Sense of it All
by Anand Lal Shimpi on October 23, 2001 2:57 AM EST- Posted in
- CPUs
Large Workload TLBs
When AMD introduced their Palomino core one of the enhancements was an increase in the number of translation lookaside buffer entries (TLB entries); an increase in TLB entries reduces the amount of time wasted going to main memory for virtual to physical address translation. Even though memory latencies are significantly reduced with the Hammer's on-die memory controller, the increase in entries does shave off previous clock cycles for certain operations. It's unclear how big of a performance boost can be attributed to the increase in TLB entry sizes, but the increases are most likely reserved for very large workload scenarios (mainly in the workstation/server arenas).
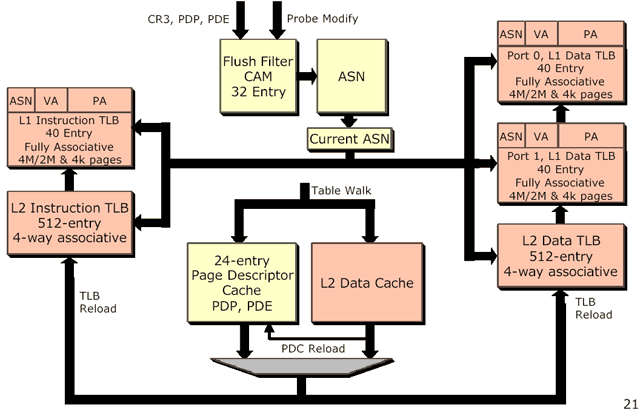
An even more interesting aspect of the Hammer's TLBs is that they are managed very well during task switches. Normally whenever a processor switches tasks, for example when working on a new thread, the processor must flush the contents of the TLBs. In a multitasking environment however, where tasks are switched to and from continuously it can be a pain to refill the TLBs over and over again. Modern day RISC CPUs use a system of assigning a process id to keep track of the contents of TLBs allowing the TLBs to be flushed when switching process ids but quickly restored when switching back to the original process. The Hammer supposedly contains similar technology.








1 Comments
View All Comments
chowmanga - Tuesday, February 2, 2010 - link
Anand, the link on page 2 leading to the discussion on the 64bit extension of the x86 is broken. Is there any way to read it?